
Our Beginner's Guide to Web Scraping
The internet has become such a powerful tool because there is so much information on there. Many marketers, web developers, investors and data scientists use web scraping to collect online data to help them make valuable decisions.
But if you’re not sure how to use a web scraper tool, it can be intermediating and discouraging. The goal of this beginner's guide is to help introduce web scraping to people who are new to it or for those who don't know where to exactly start.
We’ll even go through an example together to give a basic understanding of it. So I recommended downloading our free web scraping tool so you can follow along.
So, let’s get into it.
Introduction to Web scraping
First, it's important to discuss what is web scraping and what you can do with it. Whether this is your first time hearing about web scraping, or you have but have no idea what it is, this beginner's guide will help guide you to discover what Web scraping is capable of doing!
What is Web Scraping?
Web scraping or also known as web harvesting is a powerful tool that can help you collect data online and transfer the information in either an excel, CSV or JSON file to help you better understand the information you’ve gathered.
Although web scraping can be done manually, this can be a long and tedious process. That’s why using data extraction tools is preferred when scraping online data as they can be more accurate and more efficient.
Web scraping is incredibly common and can be used to create APIs out of almost any website.
How do web scrapers work?
Automatic web scraping can be simple but also complex at the same time. But once you understand and get the hang of it, it’ll become a lot easier to understand. Just like anything in life, you need practice making it perfect. At first, you’re not going to understand it but the more you do it, the more you’ll get the hang of it.
The web scraper will be given one or more URLs to load before scraping. The scraper then loads the entire HTML code for the page in question. More advanced scrapers will render the entire website, including CSS and JavaScript elements.
Then the scraper will either extract all the data on the page or specific data selected by the user before the project is run.
Ideally, you want to go through the process of selecting which data you want to collect from the page. This can be texts, images, prices, ratings, ASIN, addresses, URLs etc.
Once you have everything you want to extract selected, you can then place it on an excel/CSV file for you to analyze all of the data. Some advanced web scrapers can convert the data into a JSON file which can be used as an API.
If you want to learn more, you can read our guide on What is Web Scraping and what it’s used for
What Kind of Web Scrapers are There?
Web scrapers can drastically differ from each other on a case-by-case basis.

For simplicity’s sake, we will break down some of these aspects into 4 categories. Of course, there are more intricacies at play when comparing web scrapers.
- self-built or pre-built
- browser extension vs software
- User interface
- Cloud vs Local
Self-built or Pre-built
Just like how anyone can build a website, anyone can build their own web scraper.
However, the tools available to build your web scraper still require some advanced programming knowledge. The scope of this knowledge also increases with the number of features you’d like your scraper to have.
On the other hand, there are numerous pre-built web scrapers that you can download and run right away. Some of these will also have advanced options added such as scrape scheduling, JSON and Google Sheets exports and more.
Browser extension vs Software
In general terms, web scrapers come in two forms: browser extensions or computer software.
Browser extensions are app-like programs that can be added to your browsers such as Google Chrome or Firefox. Some popular browser extensions include themes, ad blockers, messaging extensions and more.
Web scraping extensions have the benefit of being simpler to run and being integrated right into your browser.
However, these extensions are usually limited by living in your browser. Meaning that any advanced features that would have to occur outside of the browser would be impossible to implement. For example, IP Rotations would not be possible in this kind of extension.
On the other hand, you will have actual web scraping software that can be downloaded and installed on your computer. While these are a bit less convenient than browser extensions, they make up for it in advanced features that are not limited by what your browser can and cannot do.
User Interface
The user interface between web scrapers can vary quite extremely.
For example, some web scraping tools will run with a minimal UI and a command line. Some users might find this unintuitive or confusing.
On the other hand, some web scrapers will have a full-fledged UI where the website is fully rendered for the user to just click on the data they want to scrape. These web scrapers are usually easier to work with for most people with limited technical knowledge.
Some scrapers will go as far as integrating help tips and suggestions through their UI to make sure the user understands each feature that the software offers.
Cloud vs Local
From where does your web scraper do its job?
Local web scrapers will run on your computer using its resources and internet connection. This means that if your web scraper has a high usage of CPU or RAM, your computer might become quite slow while your scrape runs. With long scraping tasks, this could put your computer out of commission for hours.
Additionally, if your scraper is set to run on a large number of URLs (such as product pages), it can have an impact on your ISP’s data caps.
Cloud-based web scrapers run on an off-site server which is usually provided by the company that developed the scraper itself. This means that your computer’s resources are freed up while your scraper runs and gathers data. You can then work on other tasks and be notified later once your scrape is ready to be exported.
This also allows for very easy integration of advanced features such as IP rotation, which can prevent your scraper from getting blocked from major websites due to their scraping activity.
Is Web Scraping Legal?
With you being able to attract public information off of competitors or other websites, is web scraping legal?
Any publicly available data that can be accessed by everyone on the internet can be legally extracted.
The data has to follow these 3 criteria for it to be legally extracted:
- user has made the data public
- No account is required for access
- Not blocked by robots.txt file
As long as it follows these 3 rules, it's legal!
You can learn more about the rules of web scraping here: Is web scraping legal?
Web scraping for beginners
Now that we understand what web scraping is and how it works. Let’s use it in action to get the hang of it!
For this example, we are going to extract all of the blog posts ParseHub has created, how long they take to read, who wrote them and URLs. Not sure what you will use with this information, but we just want to show you what you can do with web scraping and how easy it can be!
First, download our free web scraping tool.
You’ll need to set up ParseHub on your desktop so here’s the guide to help you: Downloading and getting started.
Once ParesHub is ready, we can now begin scraping data.
If it’s your first time using ParseHub, we recommend following the tutorial just to give you an idea of how it works.
But let’s scrape an actual website like our Blog.
For this example, we want to extract all of the blogs we have written, the URL of the blog, who wrote the blog, and how long it takes to read.
Your first web scraping project
1. Open up ParseHub and create a new project by selecting “New Project”
2. Copy this URL: https://www.parsehub.com/blog/ and place it in the text box on the left-hand side and then click on the “Start project on this URL” button.
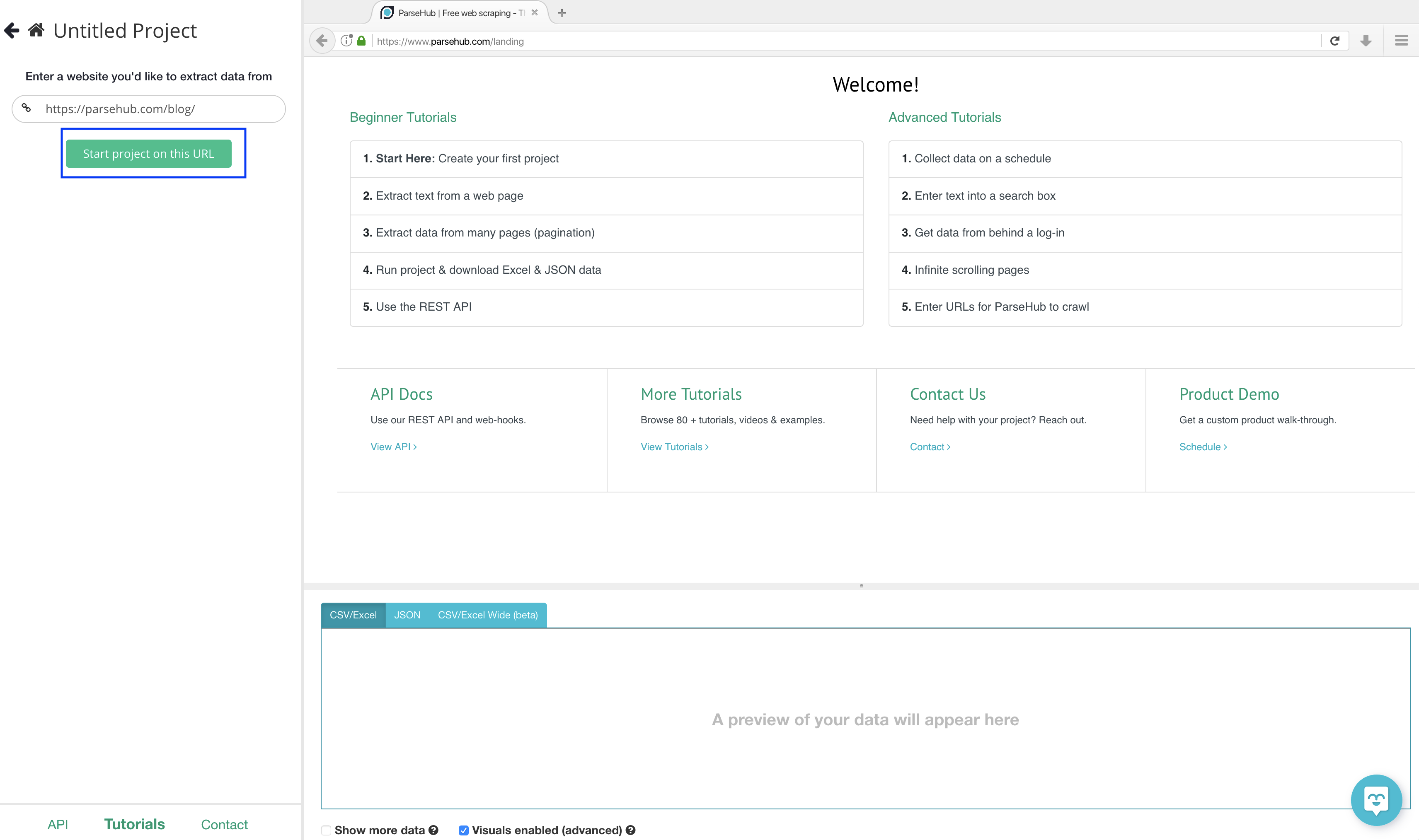
3. Once the page is loaded on ParseHub there will be 3 sections:
- command section
- the web page you're extracting from
- Preview of what the data will look like
The command section is where you will tell the software what you want to do, whether this is a click making a selection, or the advanced features ParseHub can do.
4. To begin extracting data, you will need to click on what exactly you want to extract, in this case, the blog title. Click on the first blog title you see.
Once clicked, the selection you made will turn green. ParseHub will then make suggestions of what it thinks you want to extract.
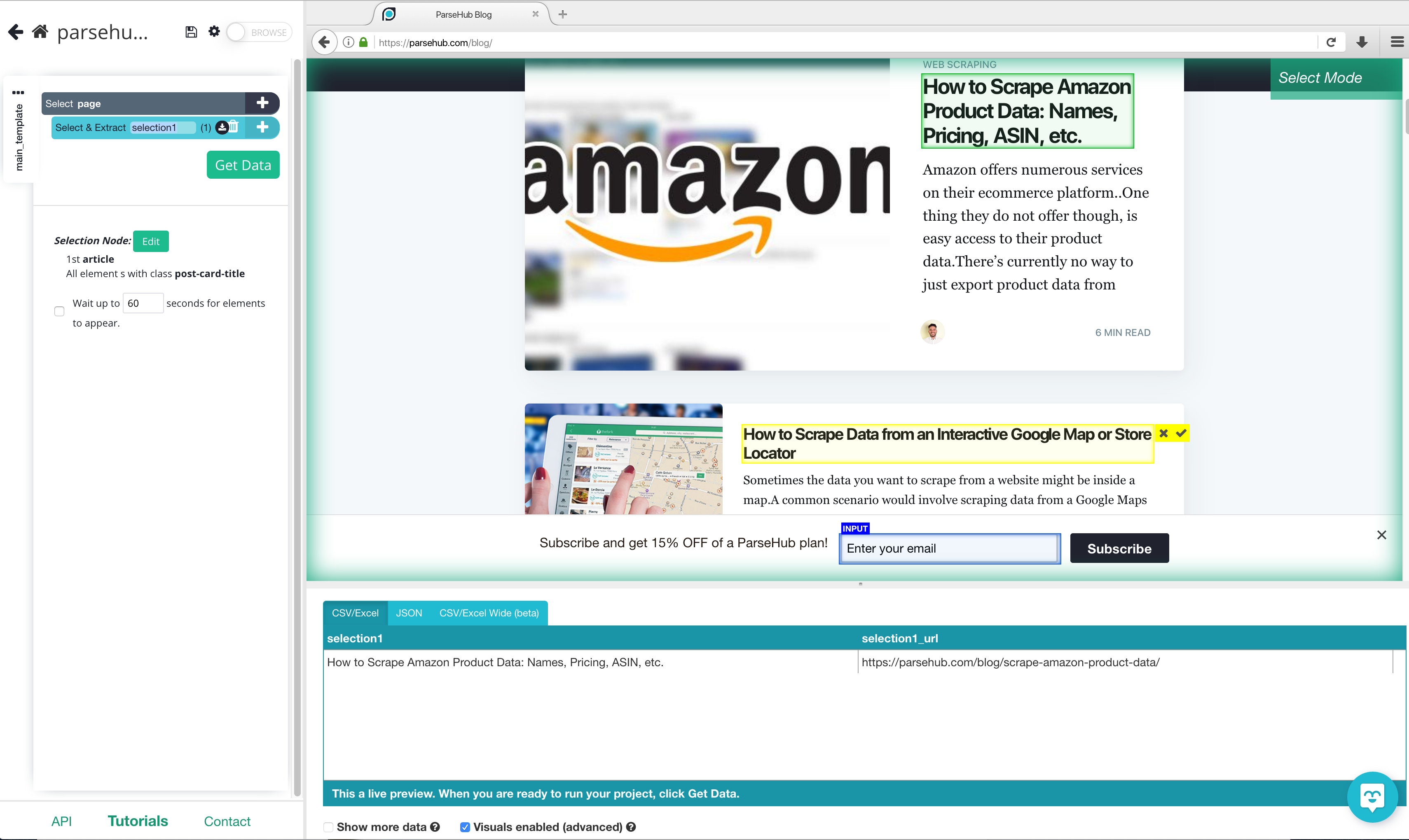
The suggested data will be in a yellow container. Click on a title that is in a yellow container then all blog titles will be selected. Scroll down a bit to make sure there is no blog title missing.
Now that you have some data, you can see a preview of what it will look like when it's exported.

5. Let’s rename our selection to something that will help us keep our data organized. To do this, just double click on the selection, the name will be highlighted and you can now rename it. In this case, we are going to name it “blog_name”.
Quick note: whenever renaming your selections or data to have no spaces i.e. Blog names won't work but blog_names will.
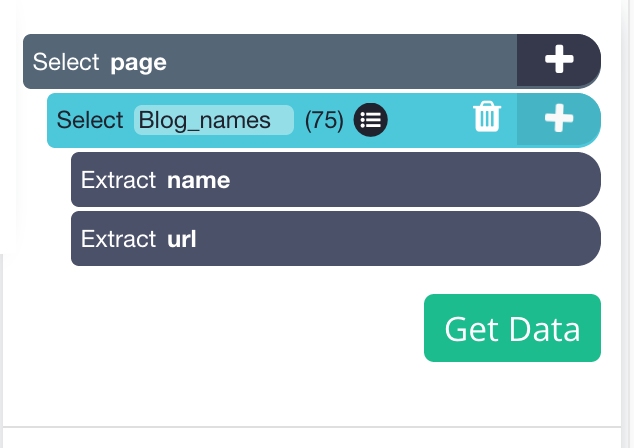
Now that all blog titles are selected, we also want to extract who wrote them, and how long they take to read. We will need to make a relative selection.
6. On the left sidebar, click the PLUS (+) sign next to the blog name selection and choose the Relative Select command.
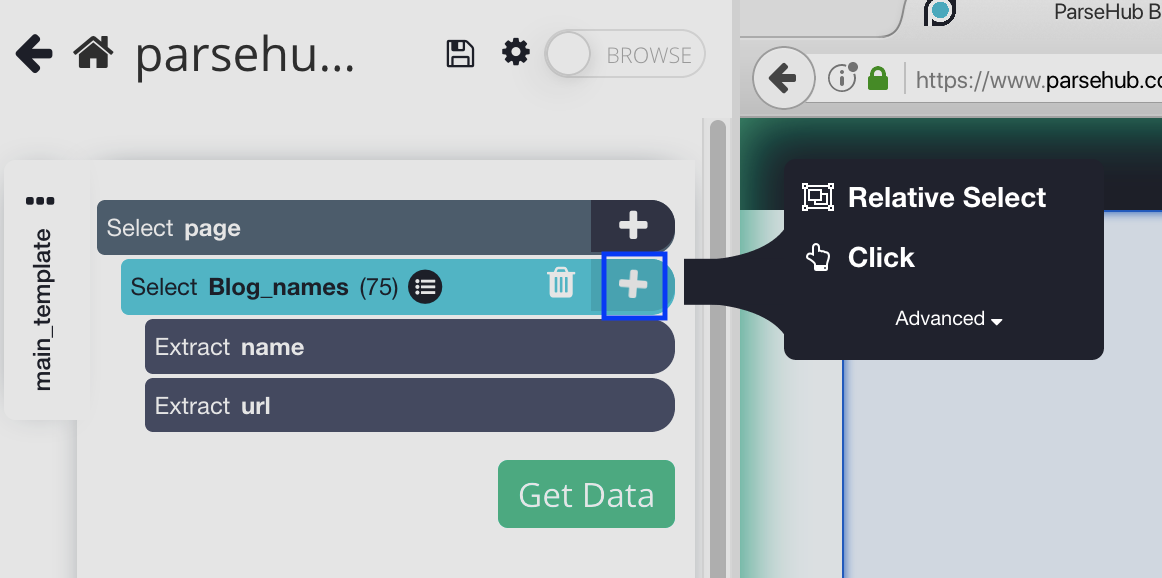
7. Using the Relative Select command, click on the first blog name and then the author. You will see an arrow connect the two selections. You should see something like this:
Let’s rename the relative selection to blog_author
Since we don’t need the image URL let’s get rid of it. To do this you want to click on the expand button on the “relative blog_author” selection.

Now select the trash can beside “extract blog_author”

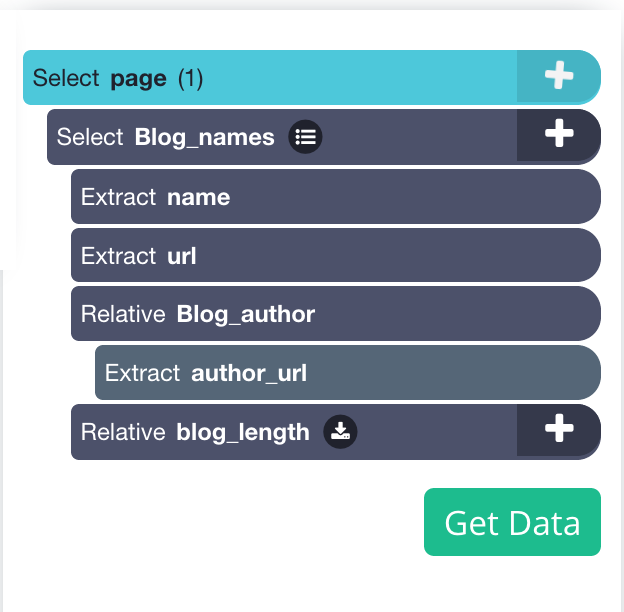
8. Repeat steps 6 and 7 to get the length of the blog, you won't need to delete the URL since we are extracting a text. Let's name this selection “blog_length”
It should look like this.
Since our blog is a scrolling page (scroll to load more) we will need to tell the software to scroll to get all the content.
If you were to run the project now you would only get the first few blogs extracted.
9. To do this, click on the PLUS + sign beside the page selection and click select. You will need to select the main element to this, in this case, it will look like this.
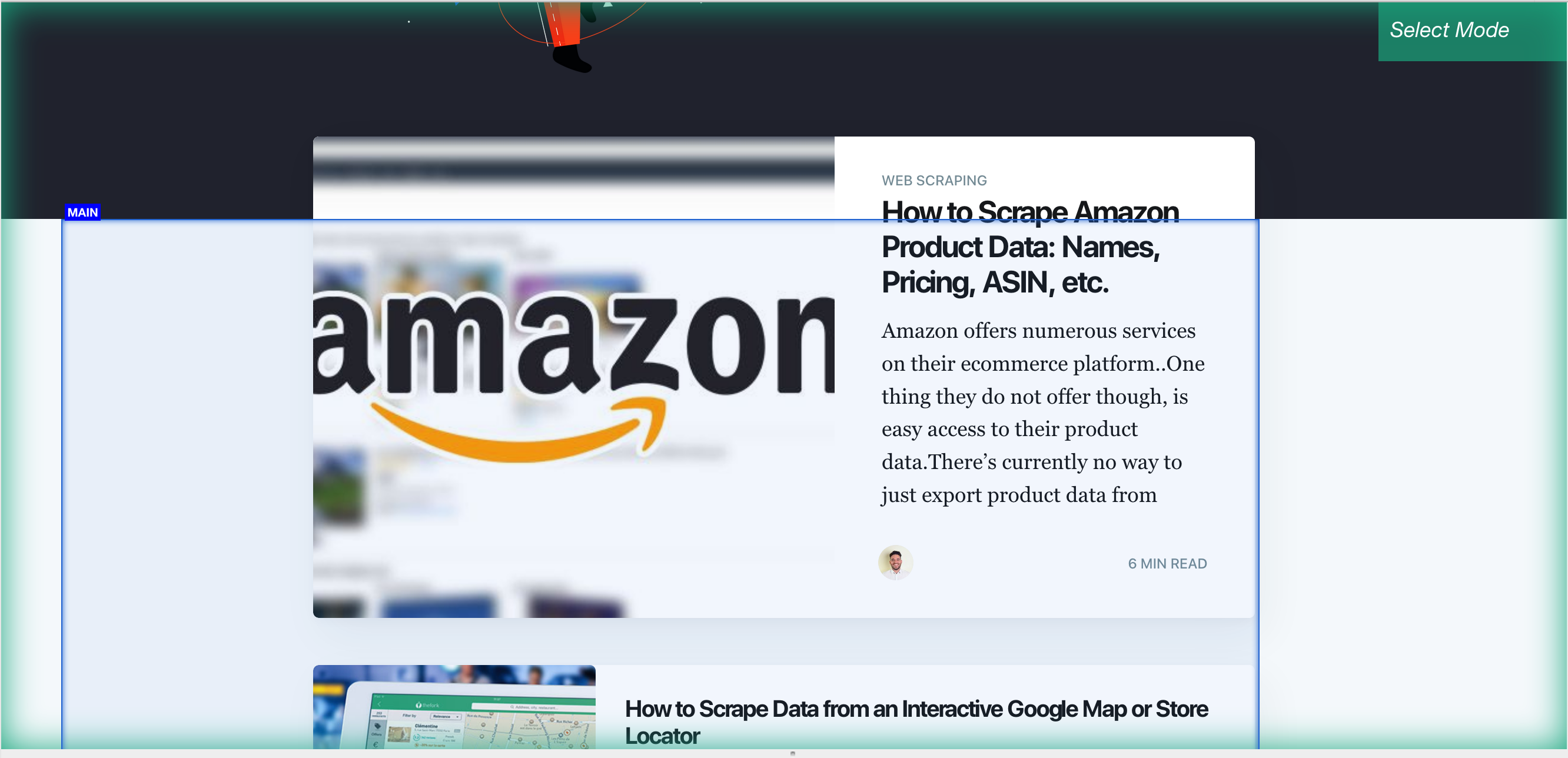
10. Once you have the main Div clicked you can add the scroll function, to do this On the left sidebar, click the PLUS (+) sign next to the main selection, click on advanced, then select the scroll function.
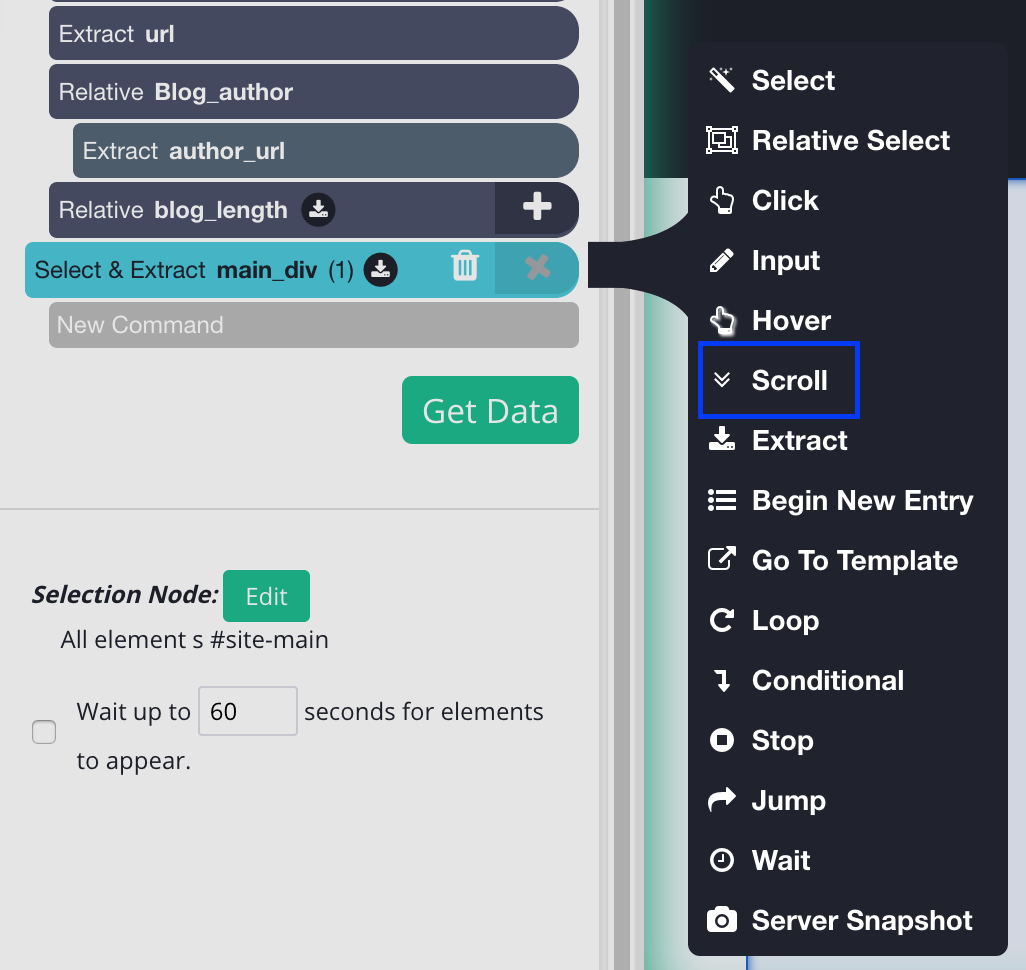
You will need to tell how long the software to scroll, depending on how big the blog is you may need a bigger number. But for now, let’s put it 5 times and make sure it's aligned to the bottom.
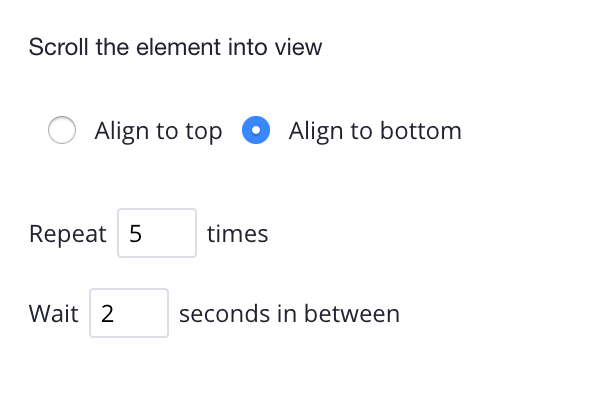
If you still need help with the scroll option you can click here to learn more.
If the blog you're trying to scrape isn't an infinite scroll, you can learn how to web scrape pagination
We will need to move the main scroll option above blog names, it should look like this now:
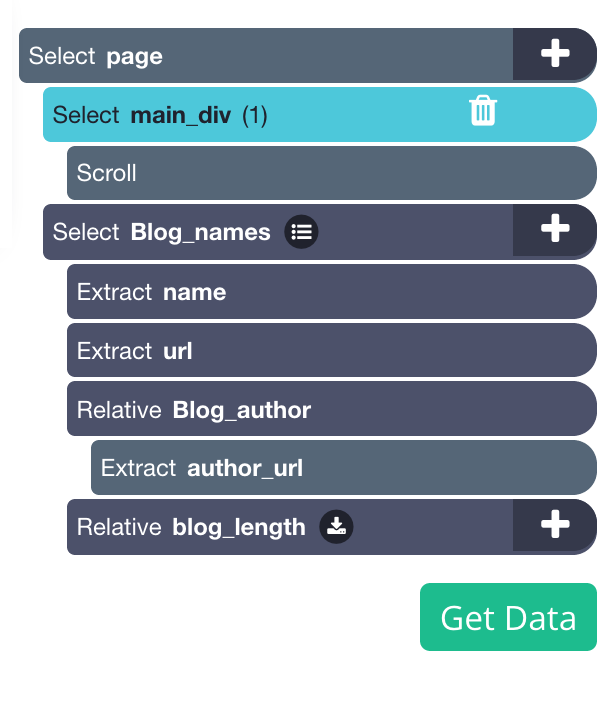
11. Now that we have everything we want to be extracted; we can now let ParseHub do its magic. Click on the “Get data” button
12. You’ll be taken to this page.
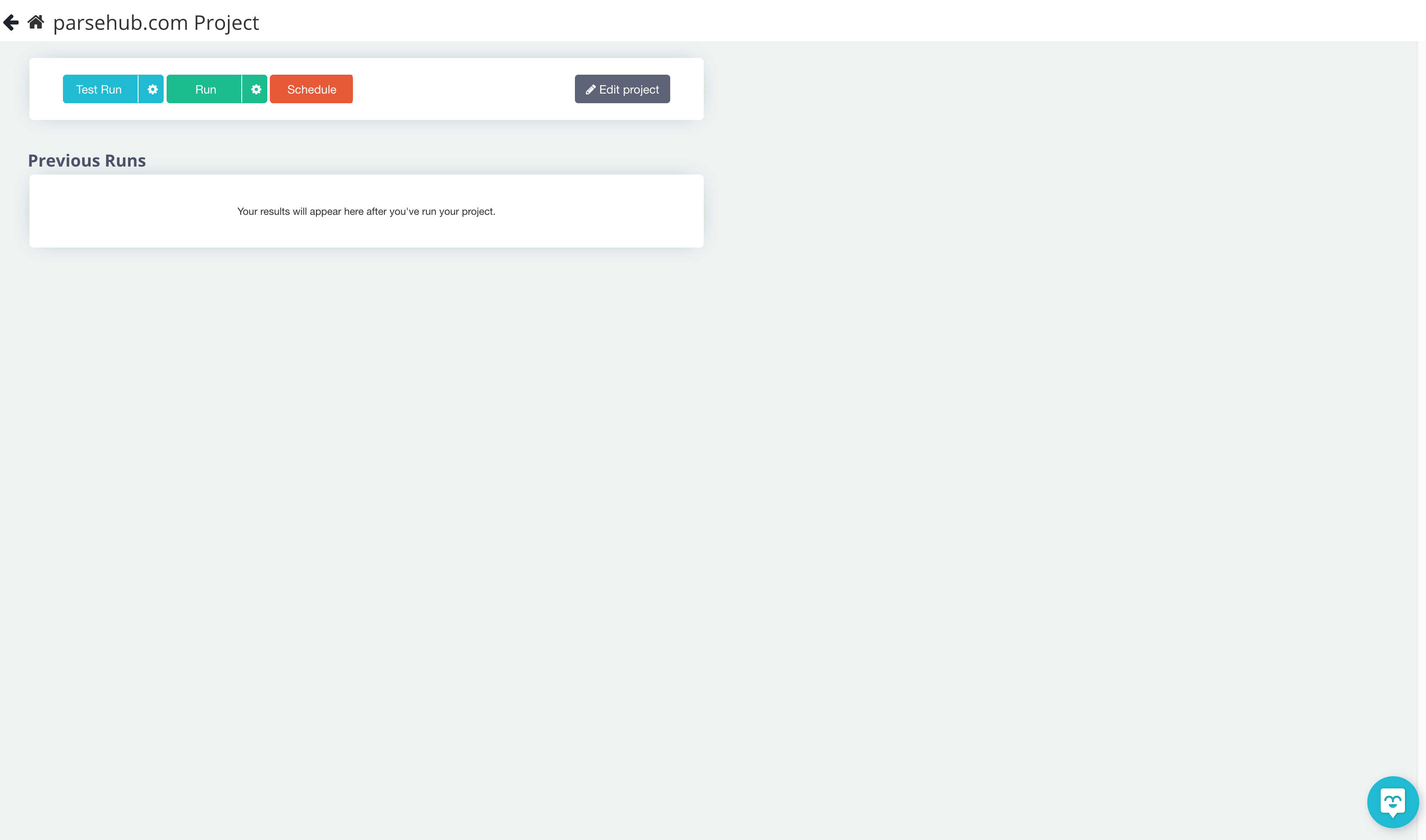
You can test your extraction to make sure it’s working properly. For bigger projects, we recommend doing a test run first. But for this project let's press “run” so ParseHub can extract the online data.
13. This project shouldn’t take too long, but once ParseHub is done extracting the data, you can now download it and export it into a CSV/Excel, JSON, or API. But we just need a CSV/ Excel file for this project.
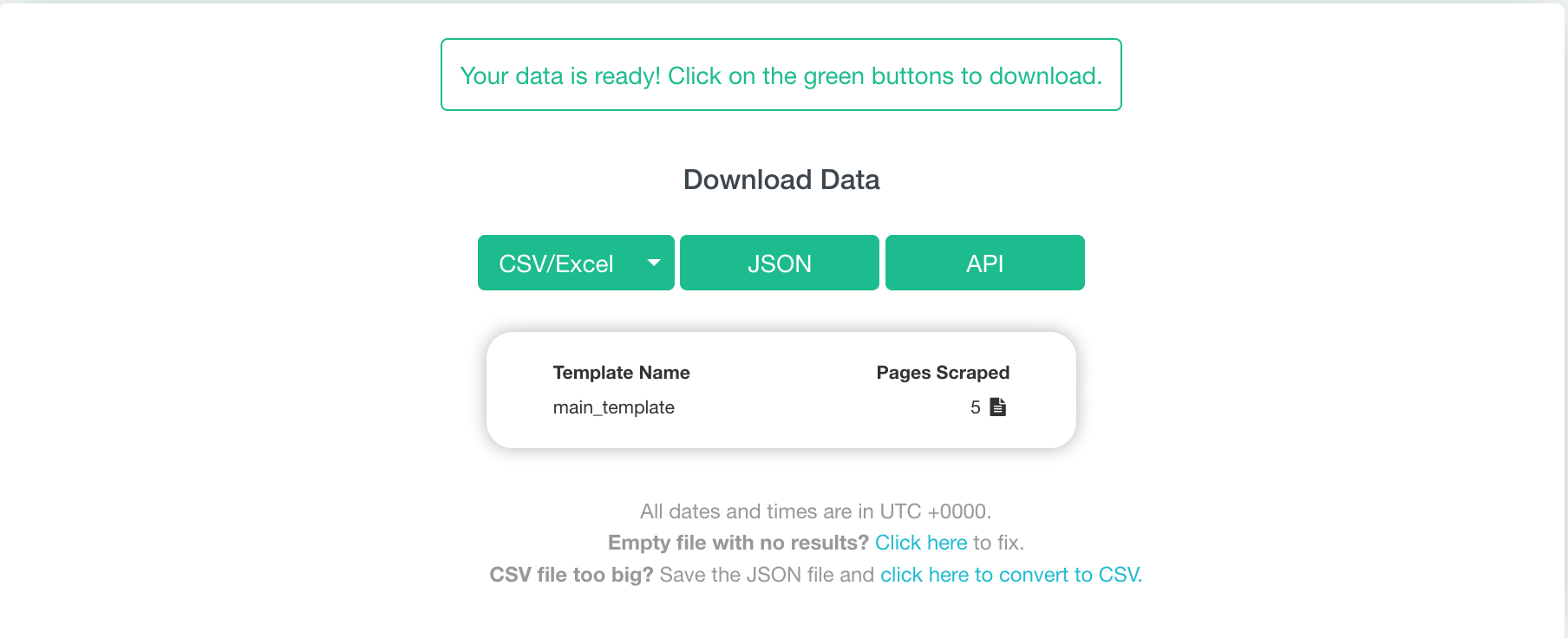
And there you have it! You’ve completed your first web scraping project. Pretty simple huh? But ParseHub can do so much more!
What else can you do with web scraping?
Now that we scraped our blog and movie titles (if you did the tutorial), you can try to implement web scraping in more of a business-related setting. Our mission is to help you make better decisions and to make better decisions you need data.
ParseHub can help you make valuable decisions by doing efficient competitor research, brand monitoring and management, lead generation, finding investment opportunities and many more!
Whatever you choose to do with web scraping, ParseHub can Help!
Check out our other blog posts on how you can use ParseHub to help grow your business. We’ve split our blog posts into different categories depending on what kind of information you're trying to extract and the purpose of your scraping.
Ecommerce website/ Competitor Analysis / Brand reputation
- How to Scrape Amazon Product Data: Names, Pricing, ASIN, etc.
- How to Scrape eBay Product Data: Product Details, Prices, Sellers and more.
- How to Scrape Walmart Product Data: Names, Pricing, Details, etc.
- How to Scrape Meta Titles and Meta Descriptions from any Website
- How to Scrape Amazon Reviews: at the step-by-step guide
- How to Scrape Etsy Product Data: Names, Pricing, Seller Information, etc.
- Scrape MercadoLibre Product Data: Names, Details, Prices, Reviews and More!
- How to Scrape Airbnb Listing Data: Pricing, Ratings, Amenities, Etc.
- How to Scrape Yelp Reviews: a step-by-step guide
- How to Scrape data from any Ecommerce Website
Lead Generation
- How to Scrape Data from an Interactive Google Map or Store Locator
- How to Scrape Search Results from a List of Keywords
- How to Scrape Yellow Pages Data: Business Names, Addresses, Phone Numbers, Emails and more.
- How to Scrape Emails from any Website: Step-by-Step Guide
- Lead Generation: How to Drastically Improve your Process Going into the 2020s
- How to Scrape Indeed Data (Job Listings, Salaries and more)
Brand Monitoring and Investing Opportunities
- How to Scrape Twitter timelines: Tweets, Permalinks, Dates and more.
- How to Scrape Yahoo Finance Data: Stock Prices, Bids, Price Change and more.
Other uses for web scraping
Closing Thoughts
There are many ways web scraping can help with your business and every day many businesses are finding creative ways to use ParseHub to grow their business! Web scraping is a great way to collect the data you need but can be a bit intimidating at first if you don’t know what you’re doing. That’s why we wanted to create this beginner's guide to web scraping to help you gain a better understanding of what it is, how it works, and how you can use web scraping for your business!
If you have any trouble with anything, you can visit our help center or blog to help you to navigate with ParseHub or can contact support for any inquiries.
Download ParseHub for Free today
Learn more about web scraping
If you want to learn more about web scraping and elevate your skills, you can check out our free web scraping course! Once completed, you'll get a certification to show off your new skills and knowledge.
Happy Scraping!