
With you being able to extract data from any website, is web scraping legal?
Many big companies and data scientists will use web scrapers to extract data needed to help them make decisions. It allows them to gather the right data for investment opportunities, product development and market research.
But first, let's quickly discuss what is web scraping then will go into more detail if web scraping is legal.
What is web scraping?
Web scraping refers to the extraction of data from a website. This information is collected and then exported into a format that is more useful for the user. Be it a spreadsheet or an API.
Although web scraping can be done manually, in most cases, automated tools are preferred when scraping web data as they can be less costly and work at a faster rate.
Is web scraping legal?
In short, the action of web scraping isn't illegal. However there are some rules that need to be followed. Web scraping becomes illegal when non publicly available data becomes extracted.

This question is asked a lot. In fact, according to Google Trends, searches for the term “web scraping legal” have been on a steady rise over the past 4 years.
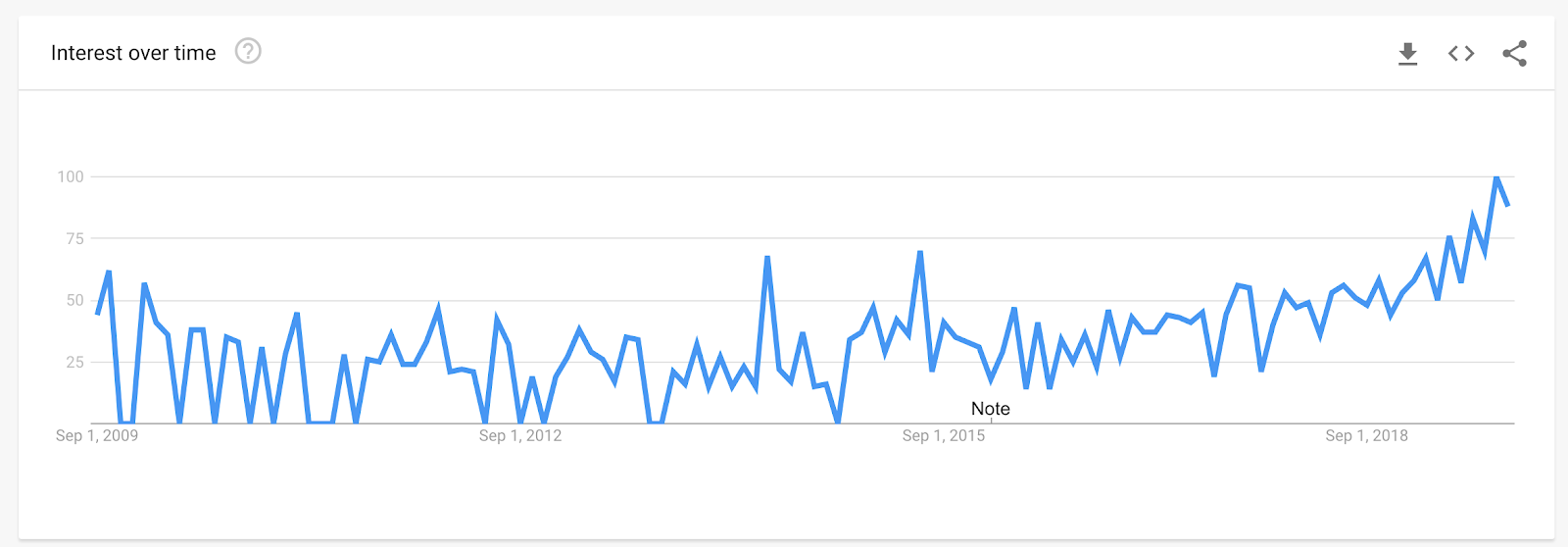
This comes as no surprise given the growth of web scraping and many recent legal cases that related to web scraping.
We are ParseHub, and we will go over a few notorious legal cases and the insight of a tech lawyer to breakdown the topic and answer the question regarding the legality of web scraping.
Web Scraping Publicly Available Data
First, we have to make a clear distinction about the type of data we are talking about when discussing the legality of web scraping.
This is data that can be accessed by anyone with an internet connection. For example, a public LinkedIn profile or a Craigslist listing.
How to know if data on the internet is considered publicly available:
- The user who posted said data has decided to make it public.
- A user does not need to create an account or login to access the data.
- The website’s robots.txt does not block web scrapers or spiders.
On the other hand, there are cases of collecting and scraping private data which exist in a completely different realm of legality. Most notably, there is the case of Cambridge Analytica and their collection of private data from Facebook Users.
In this context, we will be referring exclusively to publicly available data.
Notable Web Scraping Legal Cases
Legal cases are some of the best resources when looking at the legality of any activity. We will review 3 recent and notable legal cases surrounding web scraping:
- LinkedIn vs HiQ Labs
- Computer Fraud and Abuse Act (CFAA)
- Craiglist vs Padmapper and others

LinkedIn vs hiQ Labs
hiQ Labs is a data analytics firm that focuses on workforce data and people analytics. Their analysis provides insights for their clients about specific industries.
One of the ways that hiQ Labs collected data to fuel their insights was by scraping data from public LinkedIn profiles.
As a response, LinkedIn blocked hiQ Labs tools’ from accessing this publicly available data and served them with a cease and desist letter. Their argument was that hiQ Labs’ activities were in violation of the Computer Fraud and Abuse Act (CFAA).
hiQ went on to fight this by filling a suit and obtaining a preliminary injunction in 2017. The district court found that hiQ was “likely to succeed” on its claims that accessing publicly available data was not a violation of the CFAA.
Computer Fraud and Abuse Act (CFAA)
The thing about the Computer Fraud and Abuse Act is that it criminalizes access of protected computers and servers without authorization or beyond their authorized access.
Therefore, there is a disconnect between the CFAA and the automated access of publicly available data.
As a result, the 9th US Circuit Court of Appeals upheld hiQ’s injunction on September of 2019.
While this is not a Supreme Court ruling or the creation of a specific law that protects web scraping, it definitely paves the way for a potential future verdict.
Craigslist vs Padmapper and others
In a similar case from 2017, Craigslist filed a suit against a number of startups (including Padmapper) which scraped Craigslist data to support their services.
The defendants were worried after the trial court did not toss the case. As a result, this case was settled out of court.
Cases like these will now probably be less likely due to the hiQ Labs vs LinkedIn case.

Legal Take
Jason Tashea, a writer for ABA Journal, has published his take on the legality of web scraping as it relates to the hiQ Labs case.
In his piece, Jason calls for the US Congress or the US Supreme Court to make a decision for the legality of web scraping. He claims this is needed in order to achieve an “open and healthy internet”.
Our Take
While we are definitely not lawyers, we have a similar take to Jason’s.
If a website or user makes the decision to make their data public, then scraping it should be legal.
We believe that in 20 years, people will be surprised to learn that web scraping existed in a legal grey area during our times.
Is Web Scraping Ethical?
We consider the scraping of publicly available data to be ethical.
After all, this data is already being made available for free. There is nothing stopping you from manually writing down Amazon product prices into a spreadsheet. Web scraping just automates this process.
At the same time, we also stand against the abuse of web scraping tools. For example, we do not condone the use of web scrapers to scrape emails for mass spamming. In fact, there are more ethical ways to use web scraping for email marketing.
At the end of the day, if the data you’re scraping is publicly available and you’re not seeking to abuse web scraping tools, we’d consider it ethical.
In fact, web scrapers are a major solution when it comes to websites and services that do not provide an API.
What’s Next?
The legality of web scraping is still relatively up in the air. But that doesn’t mean web scraping is illegal, either.
However, the hiQ vs LinkedIn case might be the resolution this issue needs if there’s a verdict set by the US Supreme Court at some point.
This post was written on October 7, 2019 and last updated on July 14, 2021