
There’s always something happening on Twitter, from the latest memes to official statements from elected officials.
Not-so-surprisingly, you can learn a lot about anyone by going through their twitter timeline. And so, it can be quite useful to scrape all tweets from a specific user.
Today, we will go over how to scrape tweets from a Twitter timeline to export them all into a simple spreadsheet with all the information you’d need.
You can use this for sentiment analysis, archival purposes, market research, competitor research and much more.
Web Scraping and Twitter
First, you will need a web scraper that can deal with dynamic sites such as Twitter. In this case, we will use ParseHub, a powerful and FREE web scraper. Make sure to download it and install it on your computer.
Scraping Twitter timelines
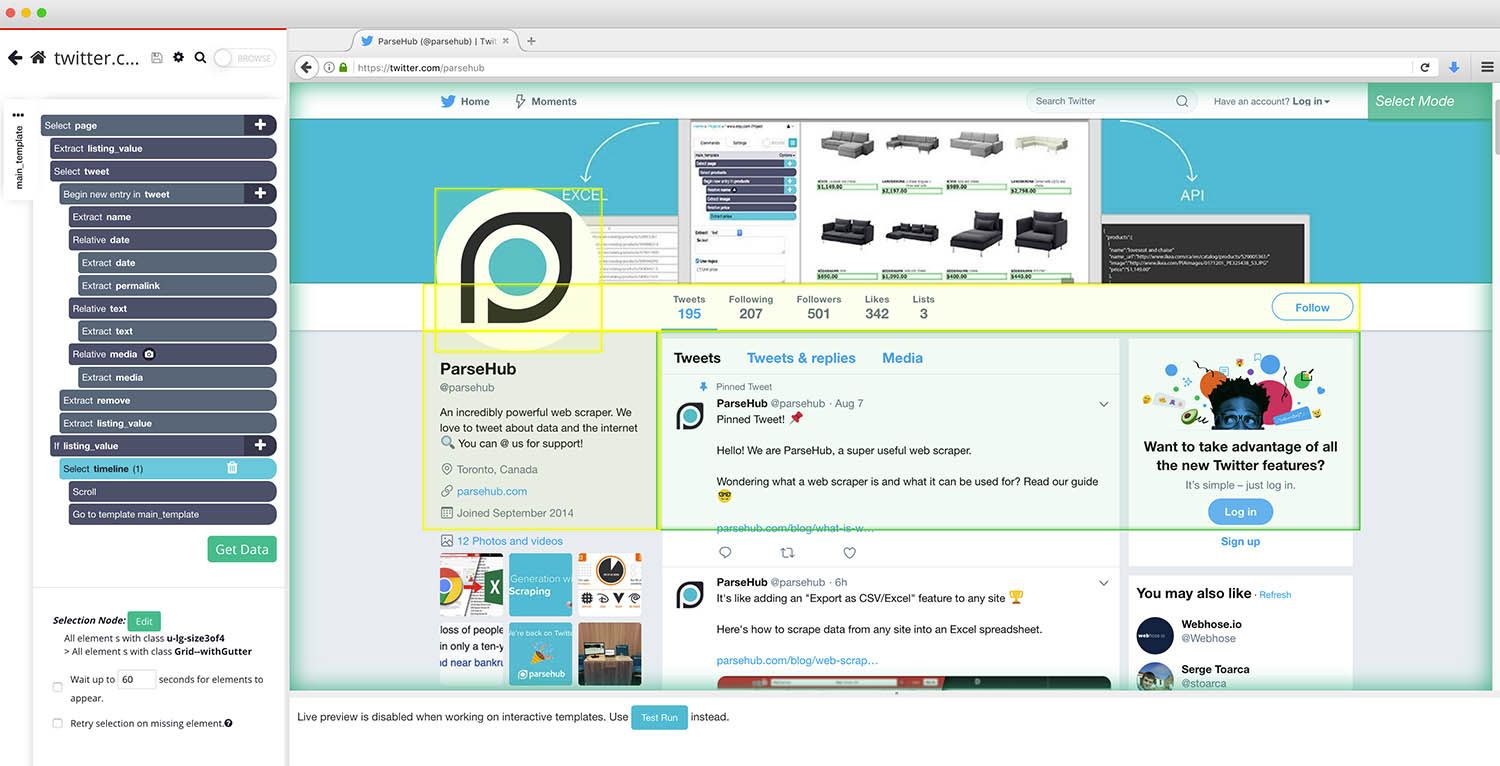
For our example today, we will be scraping our own Twitter profile @ParseHub for every tweet on our timeline.
So first, boot up ParseHub and grab the URL of the profile you’d like to scrape. Then click on New Project and enter the URL to scrape. The Twitter profile will now be fully rendered in ParseHub and you will be able to start extracting information to scrape.
Setting up your project
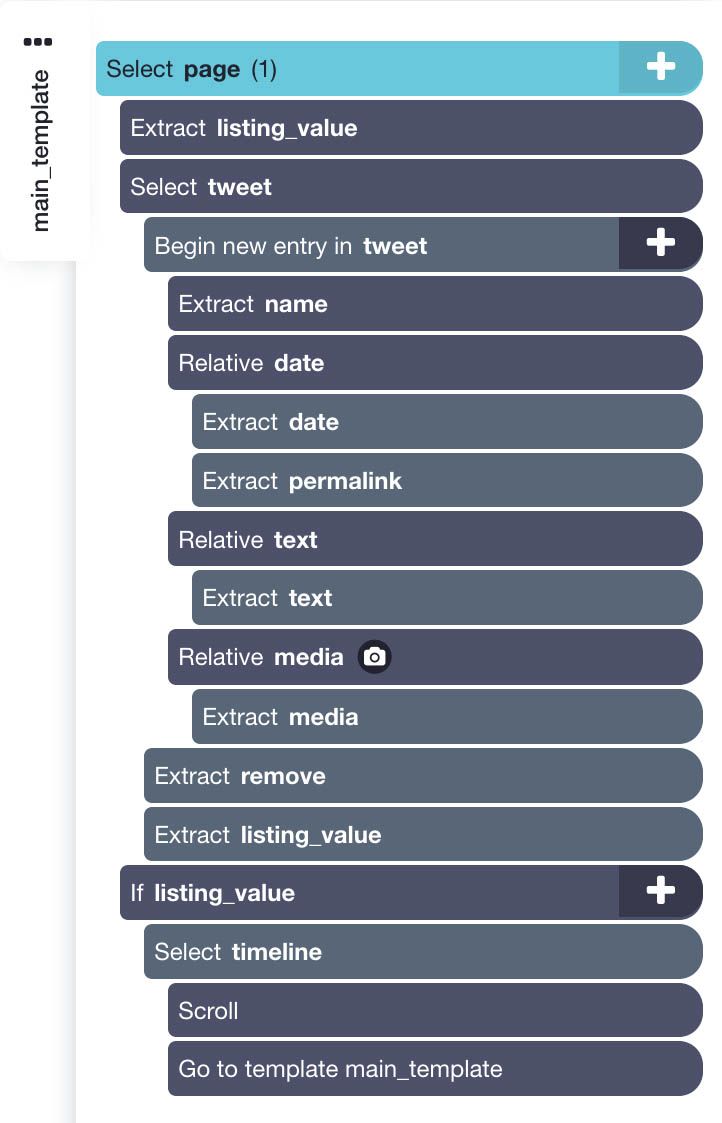
- Once the site is rendered, we will first click on the username in the first tweet in the timeline. To make sure all tweets are selected, we will also click on the username of the second tweet on the timeline. Rename your selection to tweets.
- ParseHub will automatically pull the username and profile URL of each tweet. In this case, we will remove the URL by expanding the selection and removing this extract command. Rename the other selection to name.
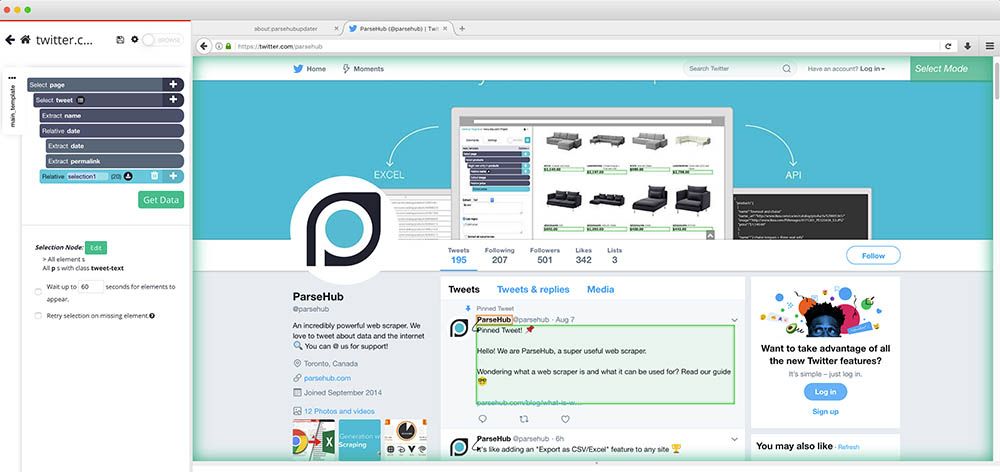
- Using the PLUS(+) sign next to the tweet command, select the Relative Select command.
- Using this command, click on the username from the first tweet we have selected and then on hover over the date on the tweet. Before clicking, you will need to press Ctrl+1 (Cmnd+1 on Mac) to select the entire date and then click on it. Then rename your selection to date.
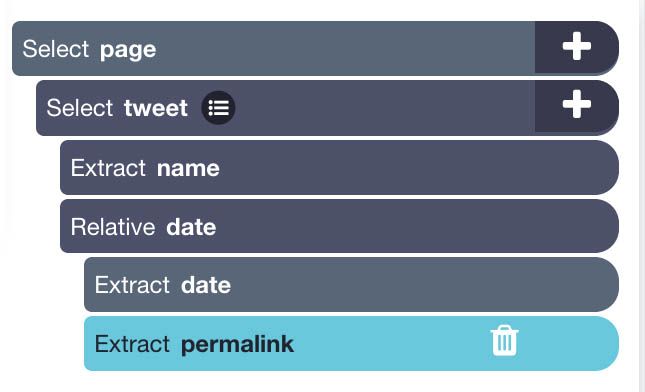
- Expand the date selection and select the first extract command, then in the dropdown below select “title Attribute”. Feel free to rename these 2 extractions accordingly to date and permalink.
- Next, click on the plus sign next to the tweet selection and choose Relative Command. Click on one of the tweets’ username first and then on the tweet text. Rename your selection to text.
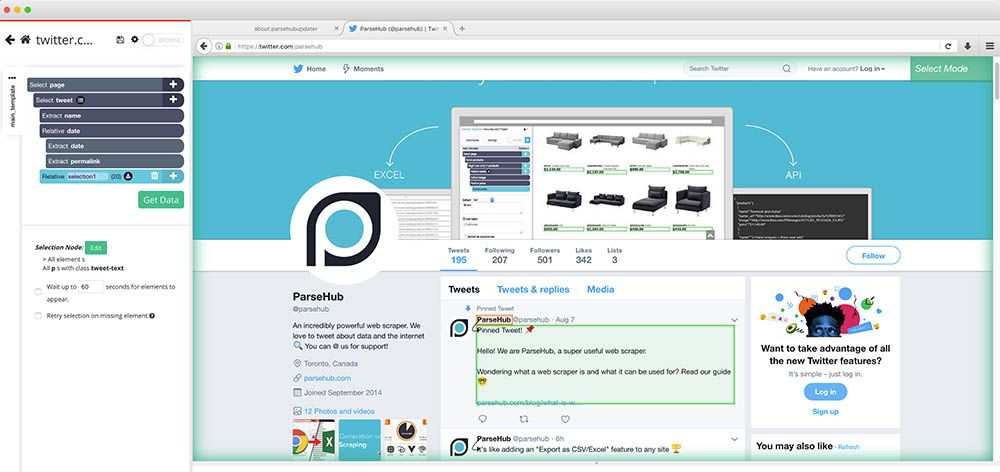
- Repeat the previous step to also extract a tweet’s media link or any other tweet information you’d like to scrape.
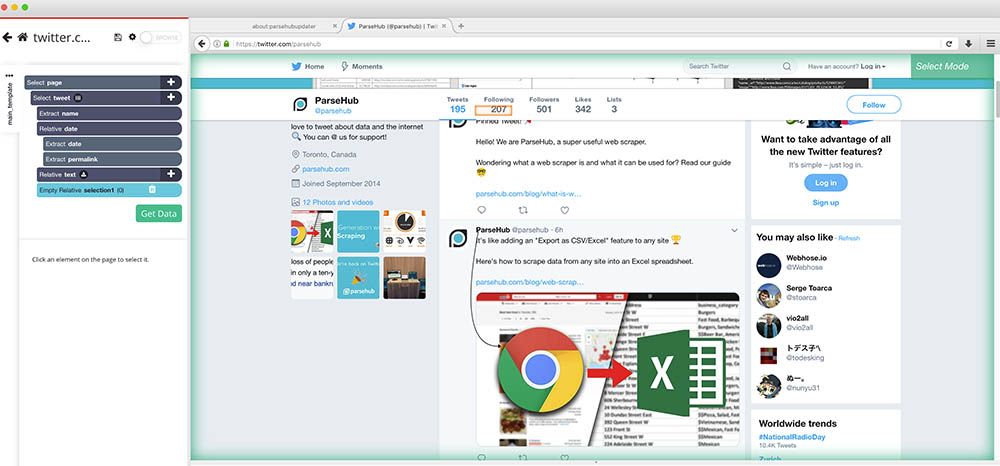
Pro Tip: Want to download all the media links from every tweet? Check out our guide on how to scrape and download images from any website.
Setting up Infinite Scroll
Now ParseHub is setup to extract info about every tweet on the page. However, Twitter works with an infinite scroll to load more tweets.
So now, we’ll tell ParseHub to scroll down to load more tweets and to delete the previously loaded tweets from the page so it doesn’t overload the page size. This can be done in just a few steps.
- Click on the PLUS(+) sign next to the page selection and select the Extract command. Rename this selection to listing_value and replace the $location.href expression with the digit 0.
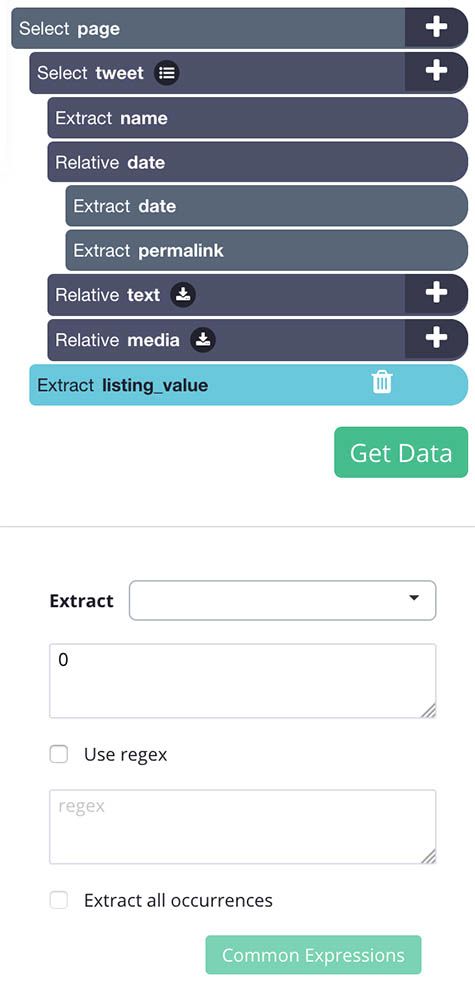
- Drag the extract command you’ve just created to the top of the command list, above the tweet select command.
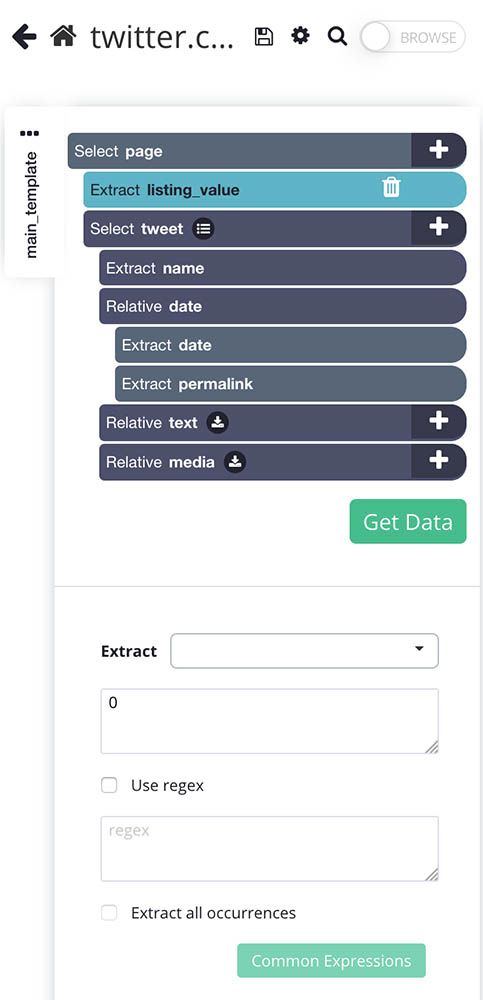
- Use the icon next to the tweet selection to expand all its commands. Hover over the tweet selection and hold the Shift key to make the PLUS(+) sign pop-up. Use the PLUS(+) sign to select an extract command.
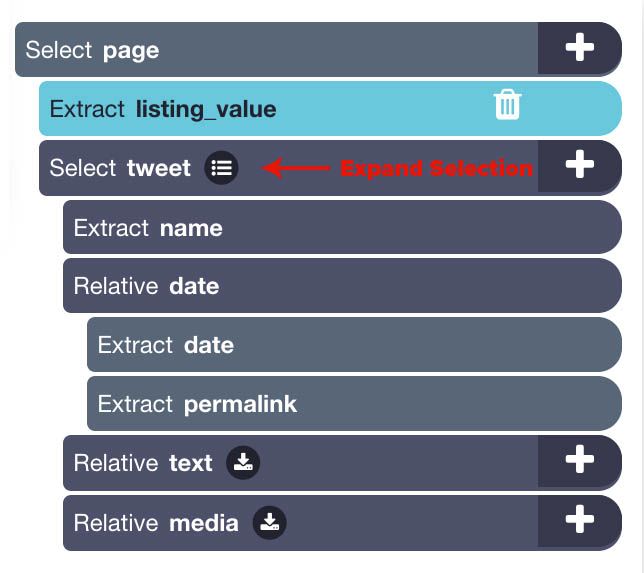
- Rename this new extract command to remove and under the extract dropdown choose “Delete element from page”
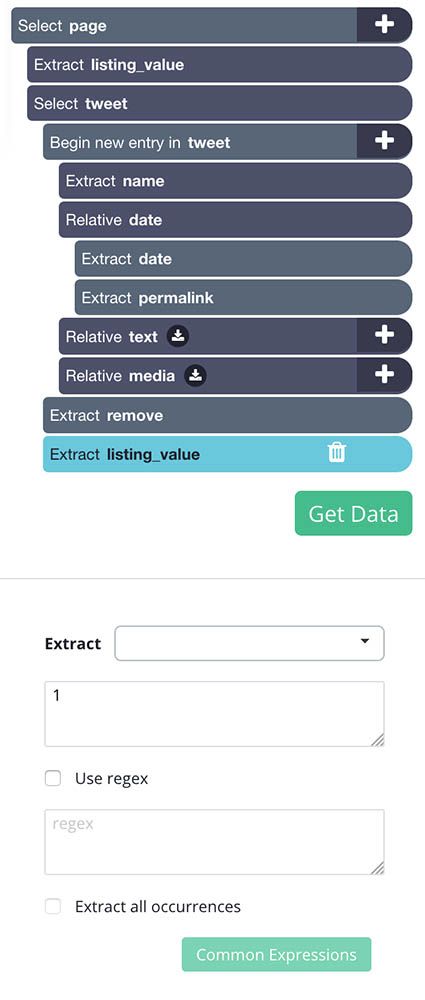
- Using the instructions in step 3, add a new extract command and name it listing_value. In the command settings below, replace the $location.href expression with the digit 1.
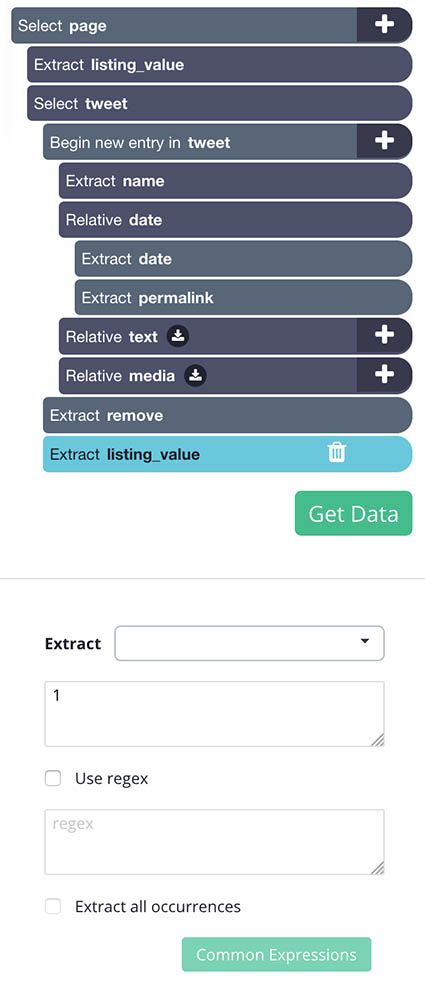
- Now click on the PLUS(+) sign next to the page selection and add a Conditional command. Edit the expression of this command to listing_value.
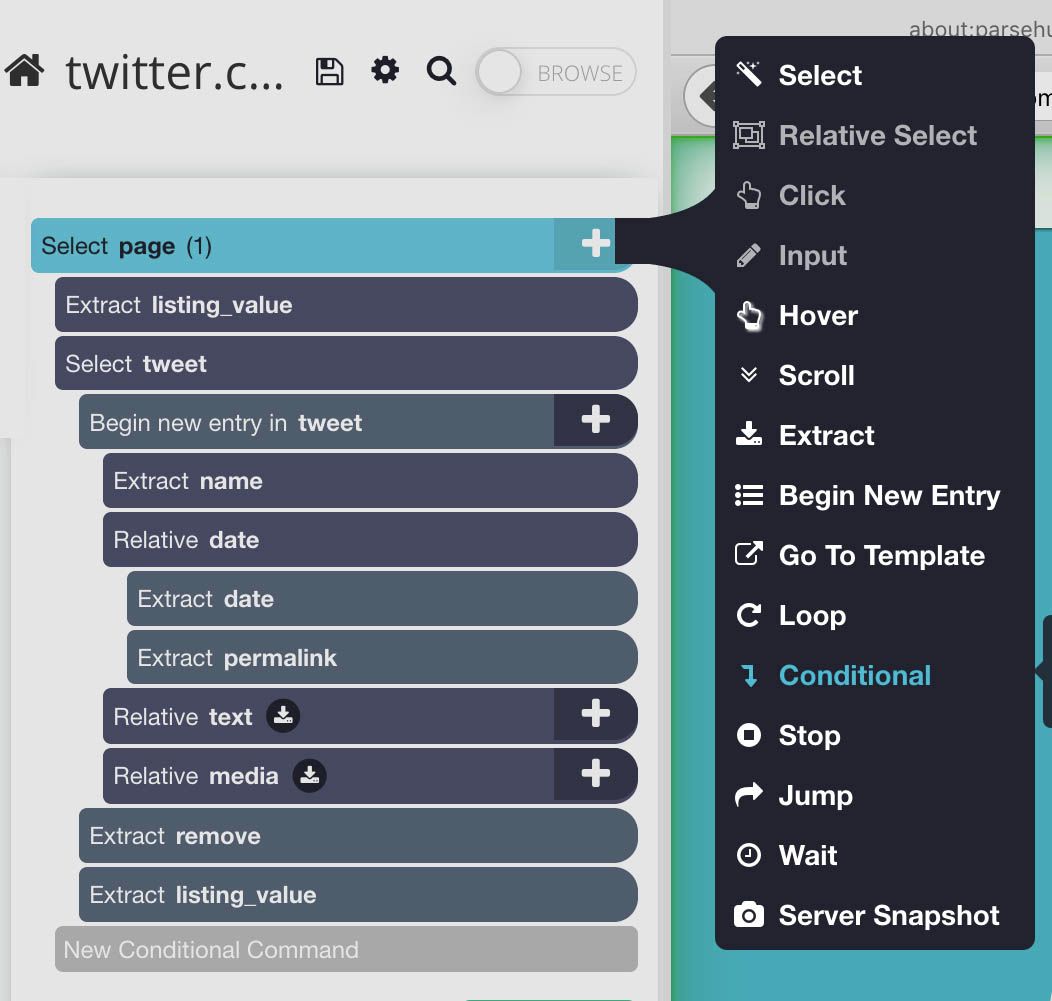
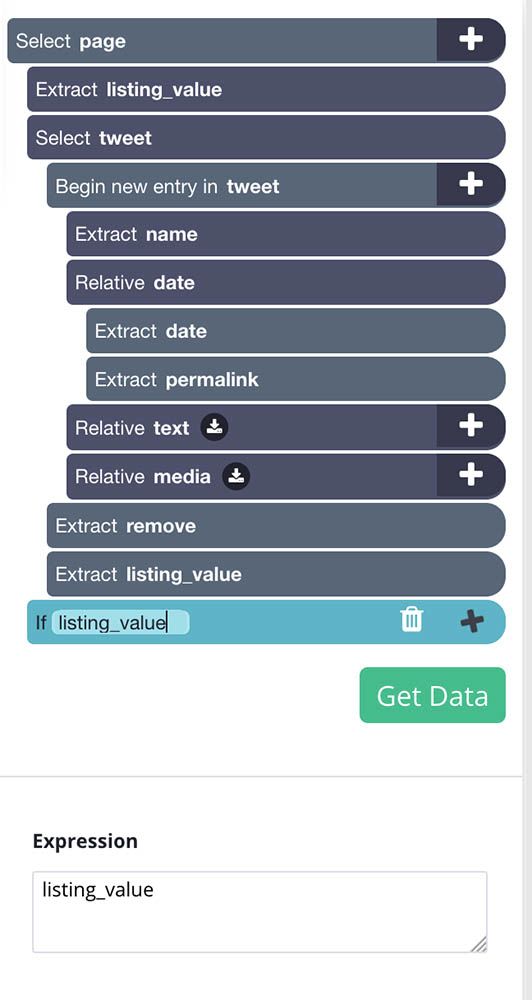
- Using the PLUS(+) sign on this conditional, add a select command and select the section on the website that contains all the tweets on the timeline. Rename this selection to timeline.
- Expand your new timeline command and remove the extract command.
- Click on the PLUS(+) sign on the timeline command. Use it to add a Scroll command.
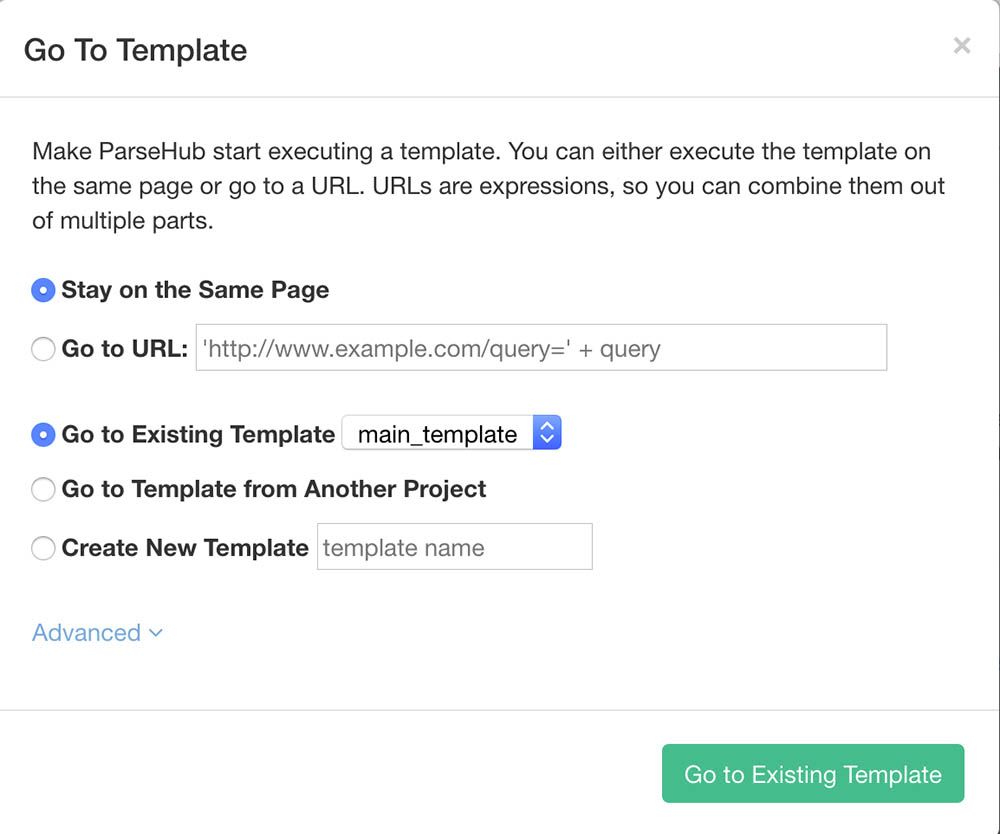
- Repeat step 9 to add a Go To Template command. A pop up will appear, accept it with its default settings.
- Lastly, click on the three dots on your left sidebar next to the main_template text and untick “No Duplicates”.
Your final project setup should look like this:
Limiting the Number of Tweets to Scrape
Some people tweet a lot. Like… A LOT.
For example, Ellen DeGeneres has tweeted over 20k times. And that is still pretty low when compared to some of the most prolific Twitter accounts out there. Just check out @akiko_lawson, a Japanese account with over 50 million tweets.
As a result, you might want to limit the number of tweets you scrape from a specific user. To do this, we will give ParseHub a limit of times it will scroll down and load more tweets.
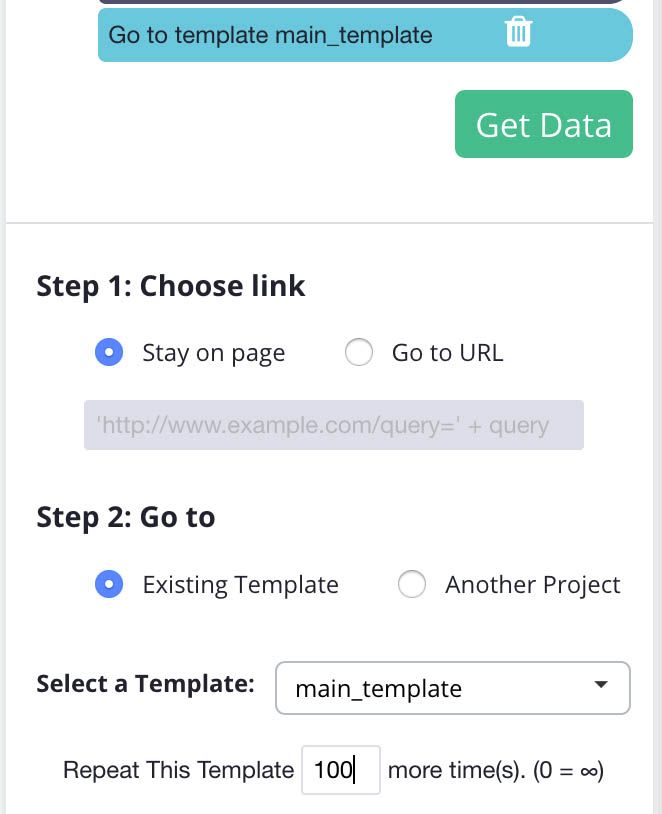
Just click on the Go To Template command you created in step 8 above and edit the “Repeat This Template” field to the number of tweets you’d like to scrape divided by 20.
For example, if you want to scrape only the 2,000 most recent tweets, input 100.
Running your Scrape
Now it’s time to run your scrape job on ParseHub. Once you’ve completed the steps above, click on the Get Data button on the left sidebar and choose Run.
Pro Tip: For larger scrape jobs, we recommend doing a Test Run first to verify that all the info you’ve selected is being scraped correctly.
Your scraping job will now run on ParseHub’s servers, meaning you are free to browse away and work on another task in the meantime. In this case, our scraping job was completed in about a minute.
Once completed, you will be notified by ParseHub and be able to download your scrape job as a spreadsheet or JSON file.
Closing Thoughts

You are now ready to scrape every single tweet by any Twitter user out there. That’s a pretty powerful tool if you know how to use it.
Which user will you scrape first?