
The website Medium is always constantly updating its website with the latest news about any topic. It allows for many writers to post about any topic to their readers.
Today we’ll show you how you can scrape the latest news from Medium without any coding skills.
Before we begin, you’ll need to download a free web scraping tool. While there are several options available, we think you’ll enjoy ParseHub! Not only is it free to use but has a suite of features like:
- Cloud-based Scraping
- Easy to use
- Scheduling
- IP rotation
- Powerful
- And many more
You can download ParseHub for free here
Now let's get started!
Web scraping news articles from Medium
If you would like to follow along with this project, you can this link to follow along
- Download and install PareseHub. Click on the new project and button and submit the URL into the text box. The website will now render inside the ParseHub.
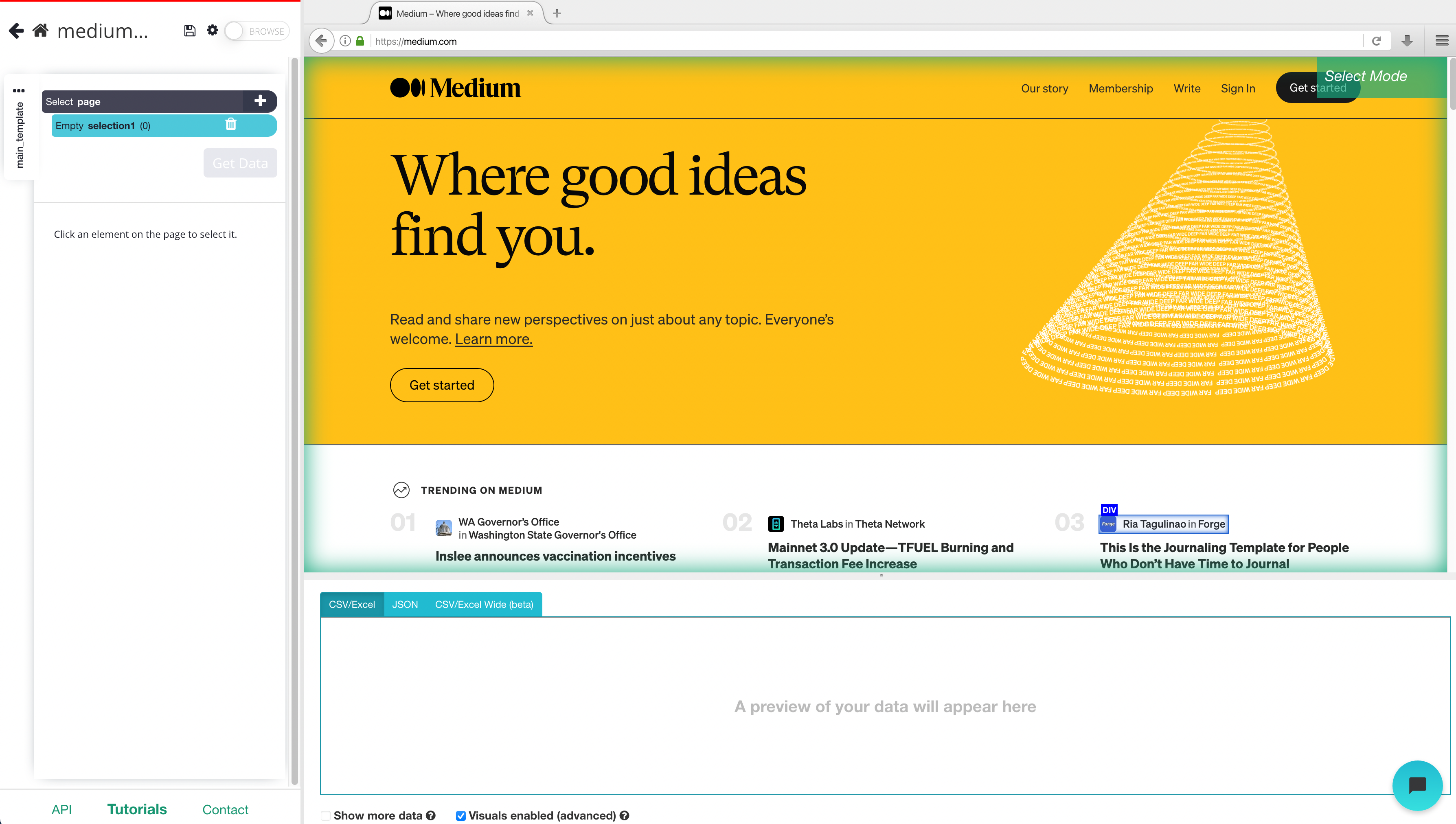
2. A select command will automatically be created. While using the select command, click on the first headline that is on the page. You should notice the headline you selected will be in green. ParseHub will now suggest which other elements you want to extract in yellow.
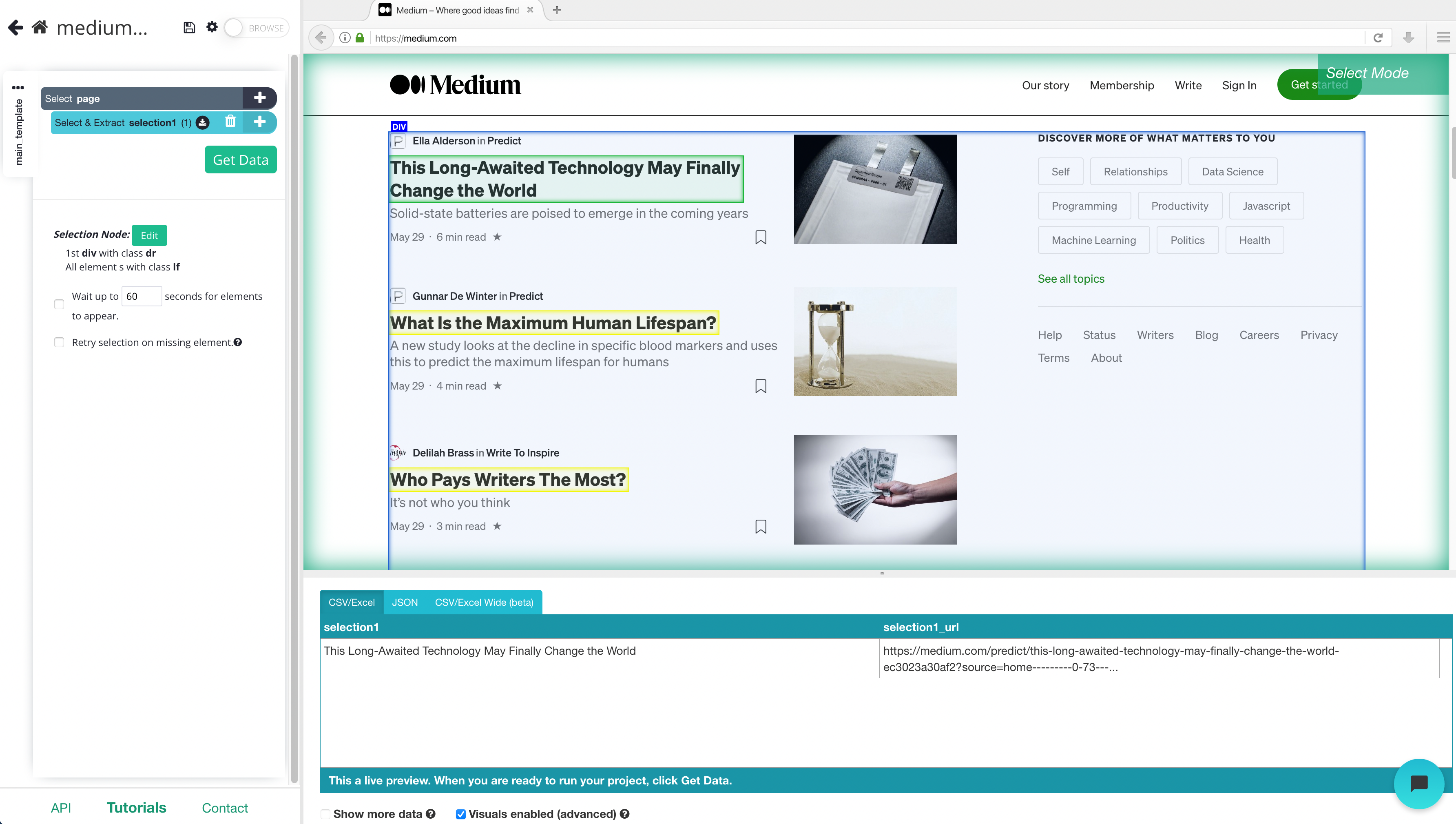
3. Click on the next headline that is in yellow to select them all. You may need to do this 2-3 times to teach ParseHub what to extract. The rest of the headlines will now be highlighted in green.
4. On the left sidebar rename your headline selection to something more appropriate, we’re going to name it “headline”
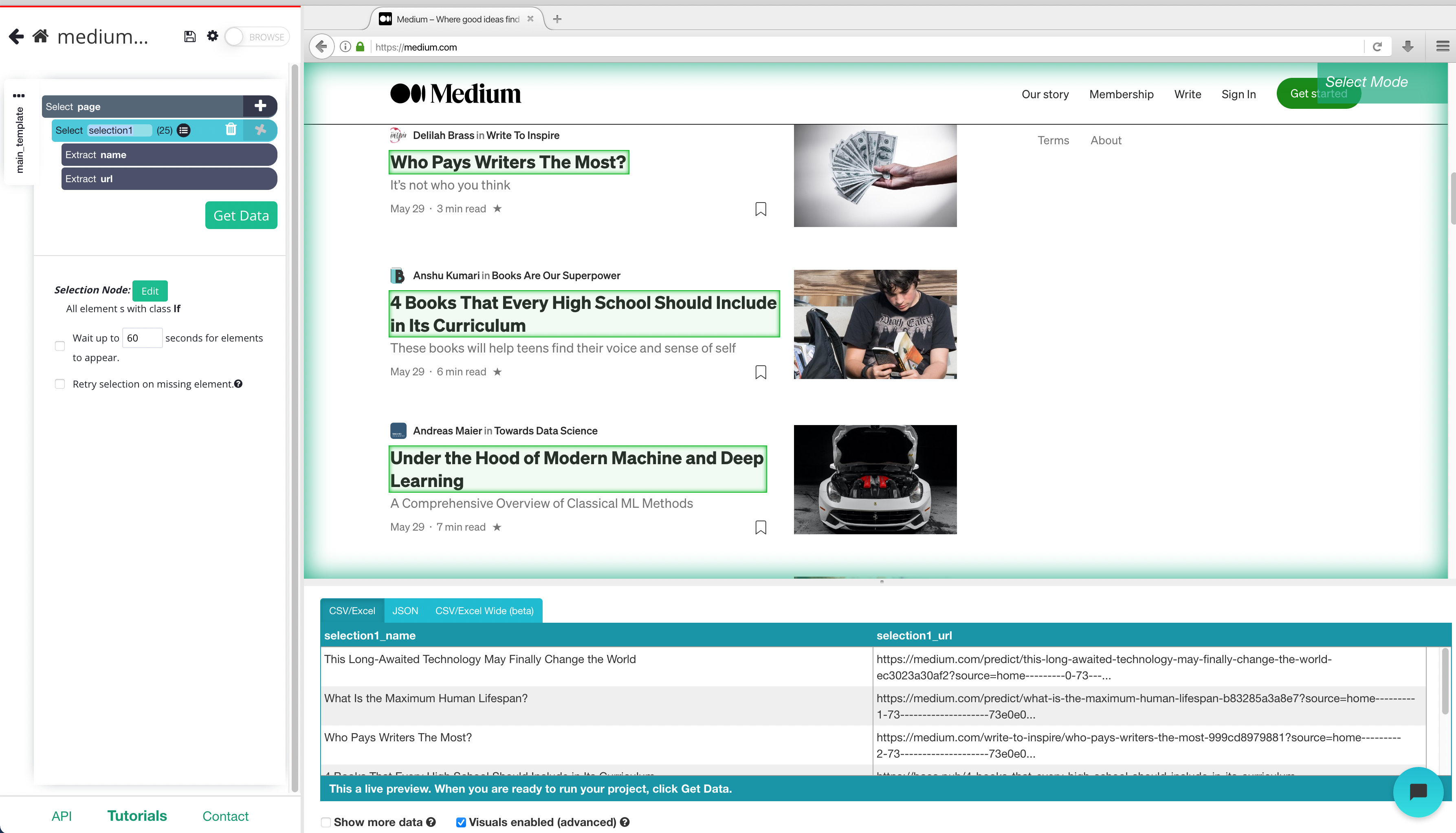
5. Click on the PLUS (+) sign next to your headline and choose the relative select command.
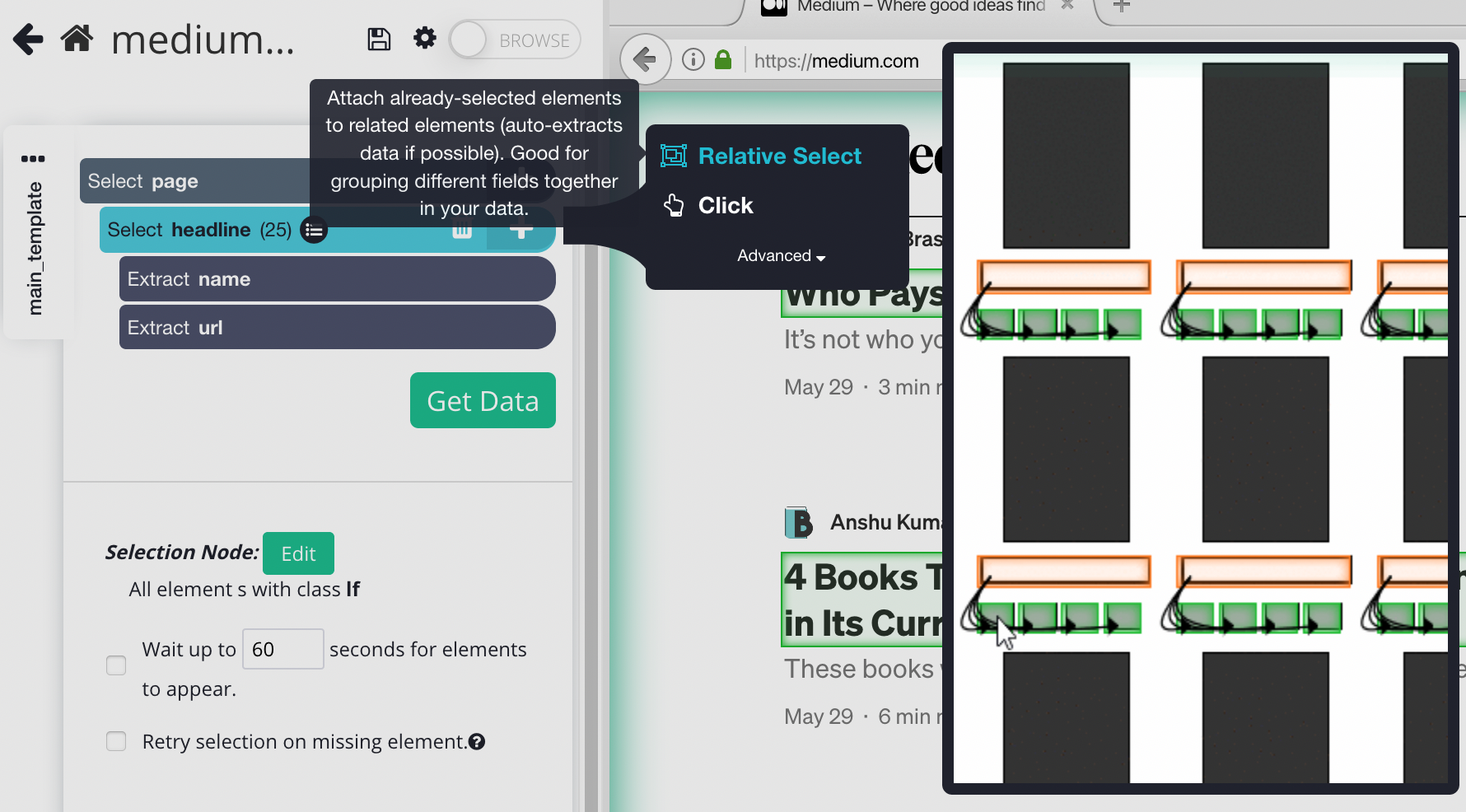
6. Click on the first headline that is highlighted in orange, then click on the description below it. An arrow will appear showing the association you have created. You may need to repeat this step to fully train the Web scraper. Rename your selection to “description”.
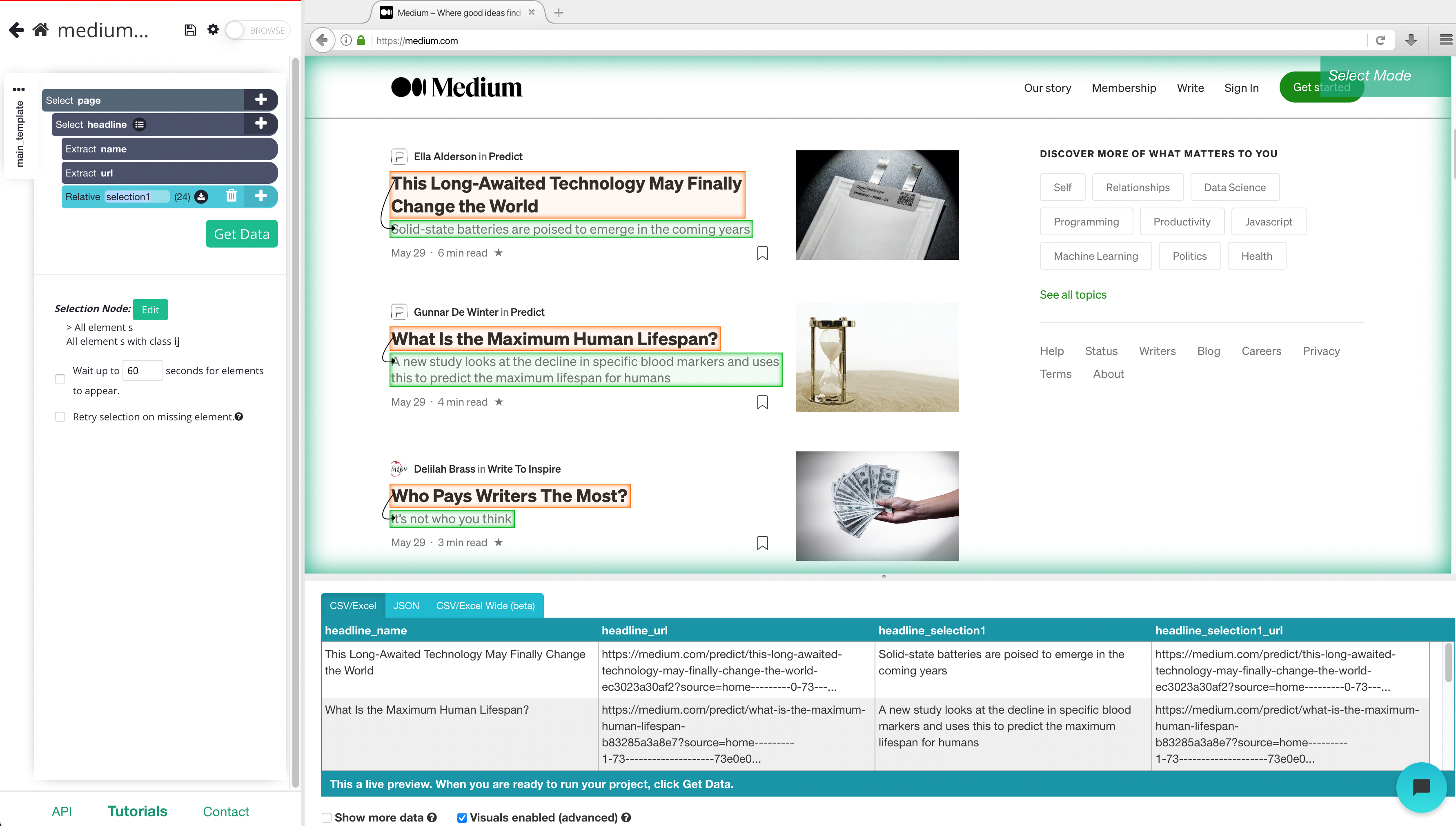
7. Repeat steps 5-6 to extract data like data posted, author and what company the author is representing.
Your template should like this for now
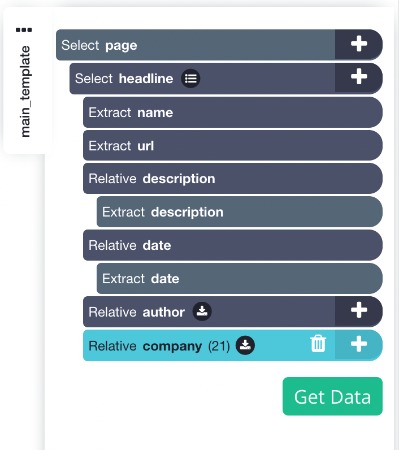
Dealing with infinite scroll
Since the blog is a scrolling page (scroll to load more) we will need to tell the web scraper to scroll to get all the content.
If you were to run the project now you would only get the first few blogs extracted. So let’s show you how you can deal with a scrolling page
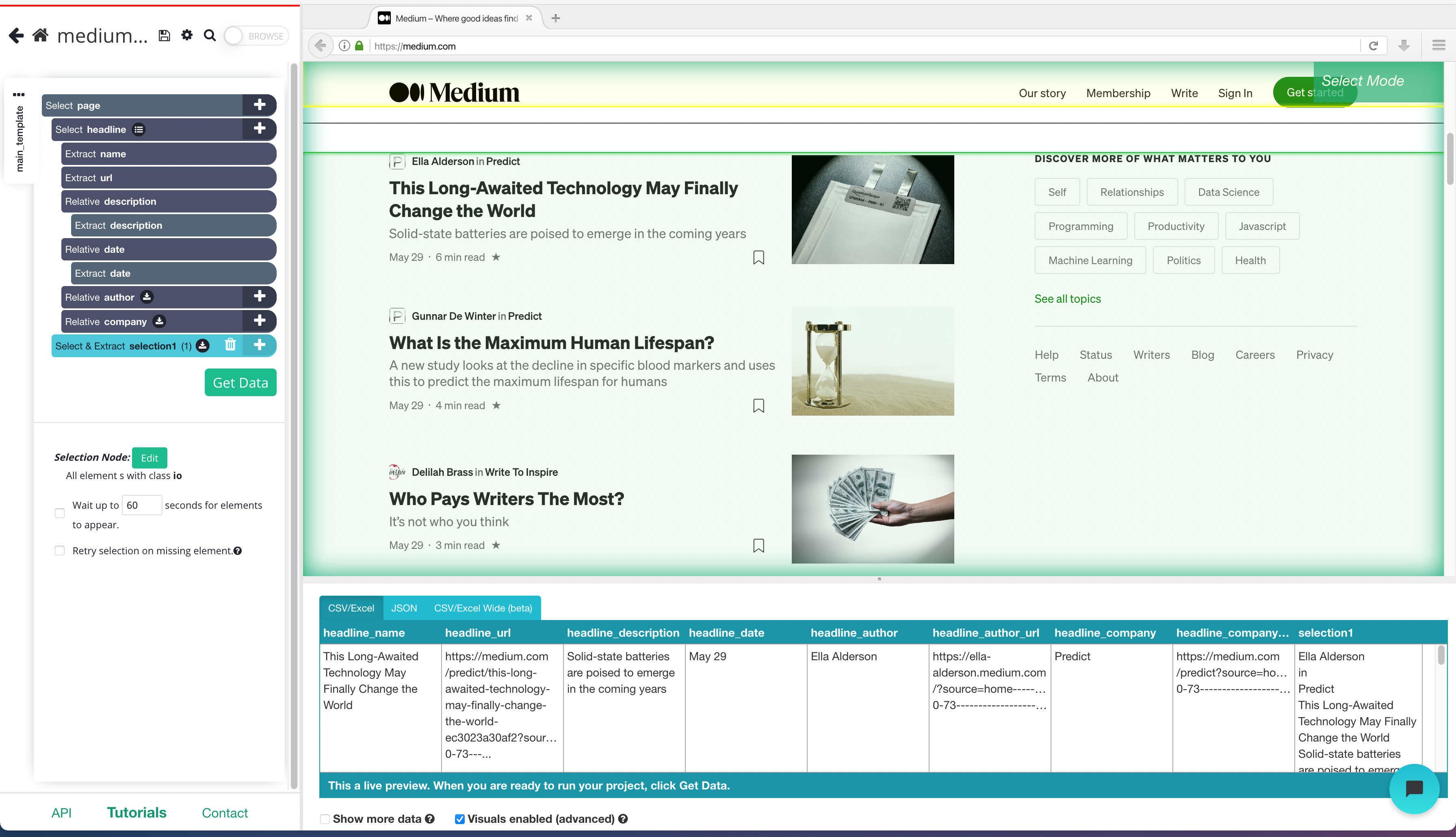
- To do this, click on the PLUS + sign beside the page selection and click select. You will need to select the main element to this, in this case, it will look like this
2. Once you have the main Div clicked you can add the scroll function, to do this On the left sidebar, click the PLUS (+) sign next to the main selection, click on advanced, then select the scroll function.
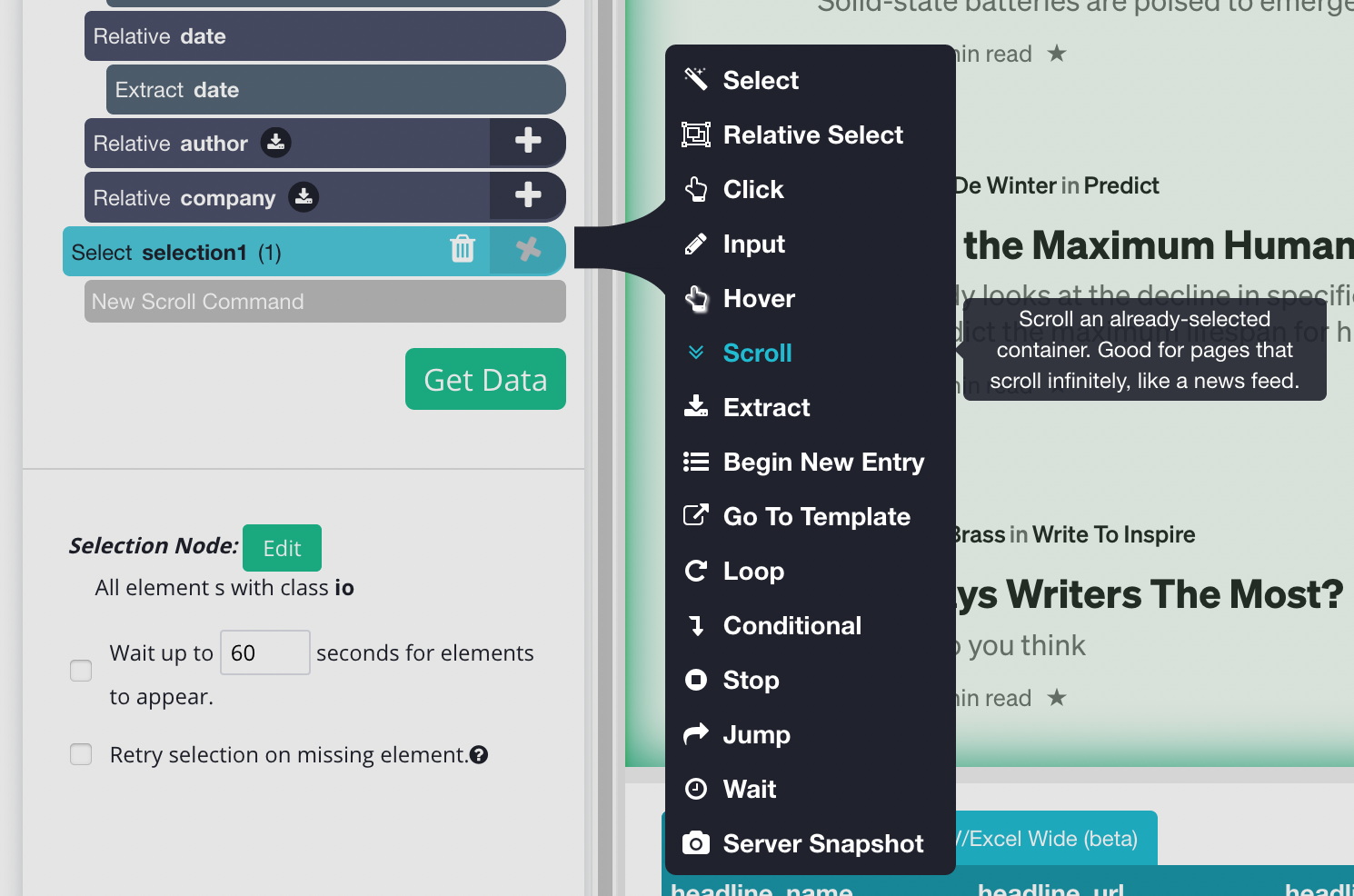
3. You will need to tell how long the software to scroll, depending on how big the blog is you may need a bigger number. But for now, let’s put it 5 times and make sure it's aligned to the bottom.
4. Now bring your scroll selection the top of your project, your final template should look like this:
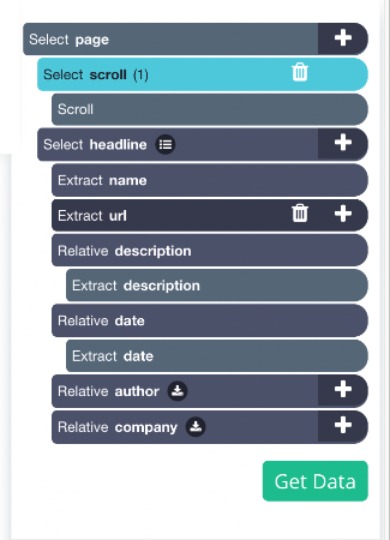
Running your Scrape
It is now time to run your scrape. To do this, click on the green Get Data button on the left sidebar. Here you will be able to test, schedule, or run your scrape job.
For larger projects, we recommend that you always test your job before running it. In this case, we will run it right away.
Once your run is completed, you will be able to download it as an Excel or JSON file.
Closing thoughts
Now you know how to scrape the latest news and articles from Medium without any coding skills. Pretty easy huh?
The great thing about this guide is that you can use this to scrape other news/blog websites to get the latest content and get new content ideas.
You can view our other guides