
Every business should have a blog! Not only does it attract new customers, but it also builds customer trust and loyalty.
It can be difficult to think of what kind of content to create or what keywords to target. A great performing blog post can attract your customers to your website with the proper SEO.
There’s no need to reinvent the wheel, so why not scrape your competitors’ blog?
We are ParseHub, and today we’ll show you how to quickly scrape blog posts to create a list of blog ideas in just a few minutes! You can also use this list to do some competitor analysis and see what keywords your competitors are targeting.
So let’s dive right into it!
Creating a list of blog ideas
To get started, you will need to download a free web scraper. We obviously recommend using ParseHub, it’s easy to use, cloud-based scraping, and many features we think you’ll enjoy!
If you’re new to web scraping, you can read our blog post to understand what is web scraping and what its used for
You can Download ParseHub for free
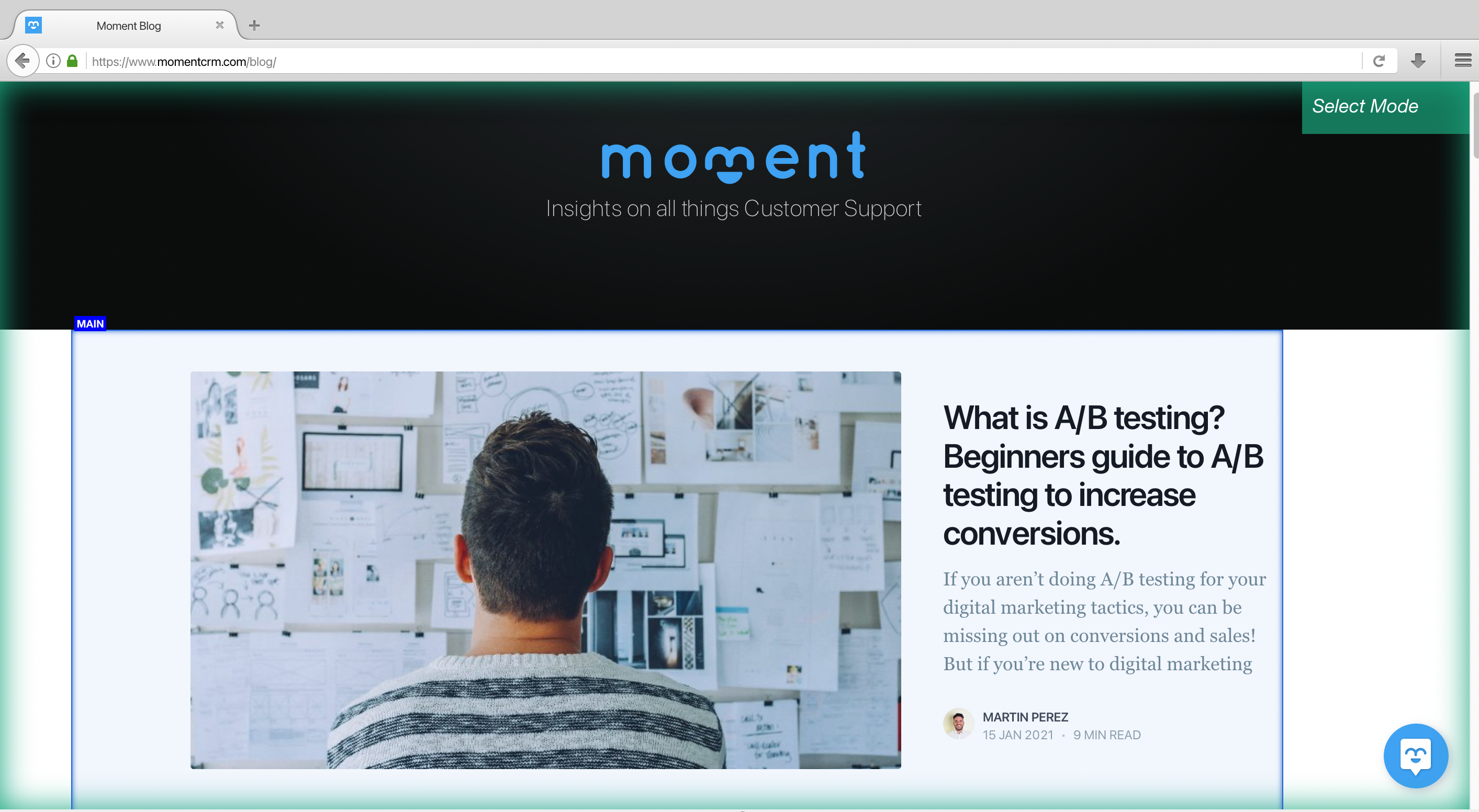
You’ll also need to choose which blog you want to scrape. For this project, we are going to scrape Moment. They’re not a competitor but they have great blog posts like:
- How to increase your conversion rate
- How to add a live chat to your website
- How to increase user interaction
So let’s get into it!
Scraping content data from a blog
Now it’s time to start setting up your web scraping project.
- Install and open ParseHub. Click on “new project” and enter the URL for the page you will be scraping. In this case, we will be scraping Moment’s Blog. Once submitted the URL will render inside the app.
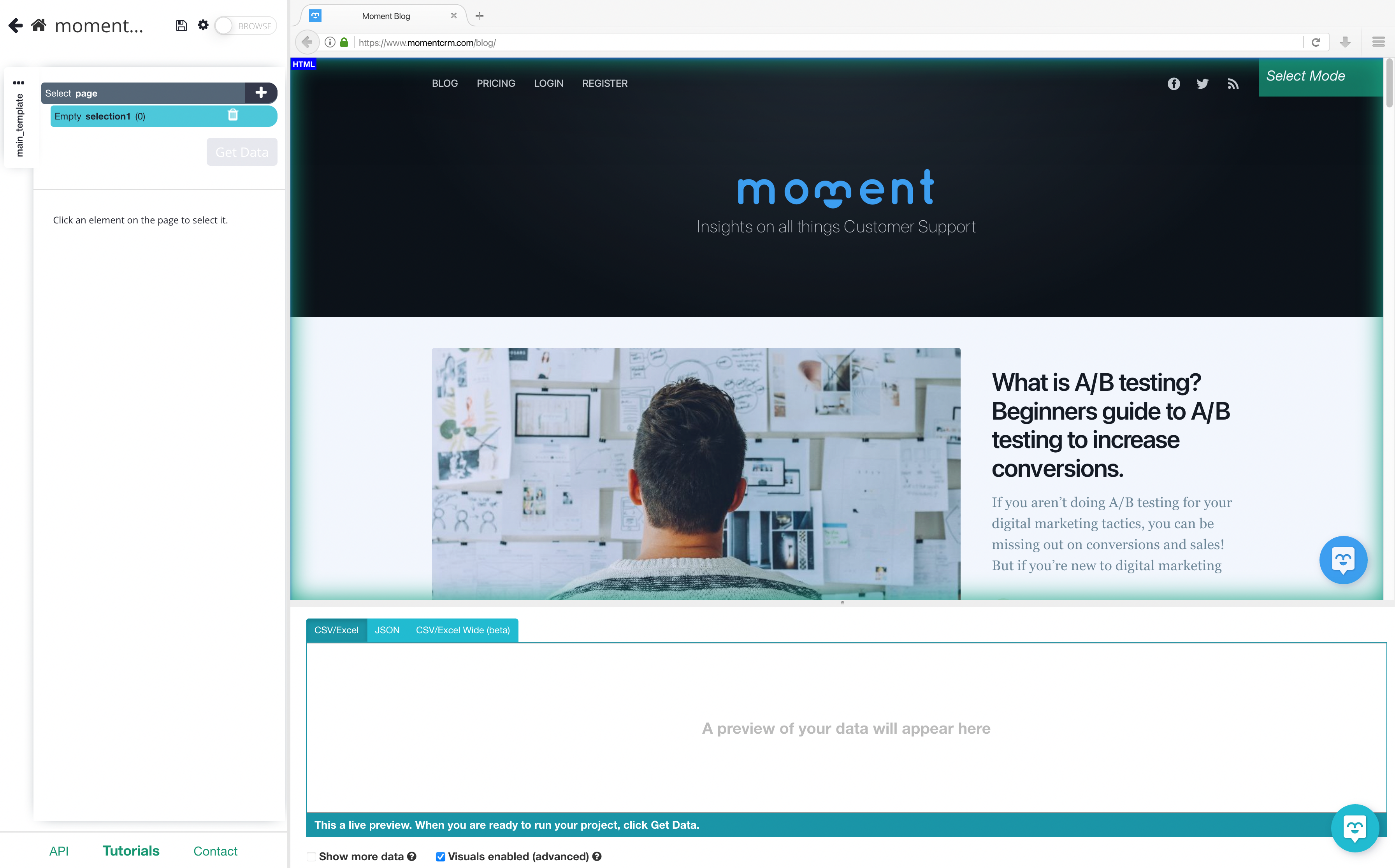
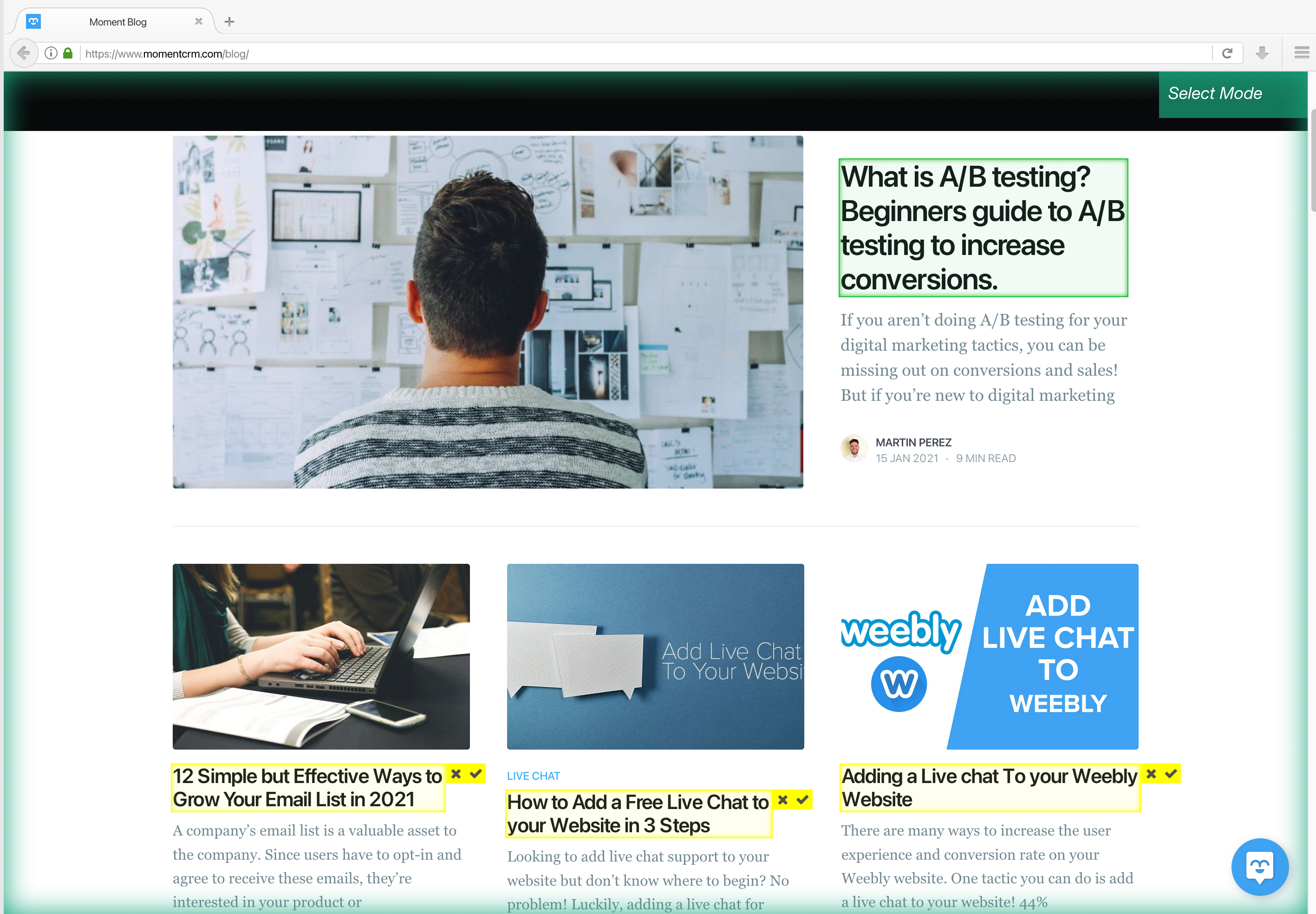
2. A select command will automatically be created, start by clicking on the first blog title on the page. It will be highlighted in green to indicate that it’s been selected. The rest of the blog posts on the page will be highlighted in yellow. In the left sidebar, rename your selection to “blog_title”.
3. Now click on the second blog title on the page to select them all. They should all be highlighted in green. If not, continue to click on the blog titles to teach ParseHub what to extract.
4. Now we can extract more data from this page. Let’s start with the date. Use the PLUS (+) sign next to your “blog_title” selection and choose the Relative Select command.
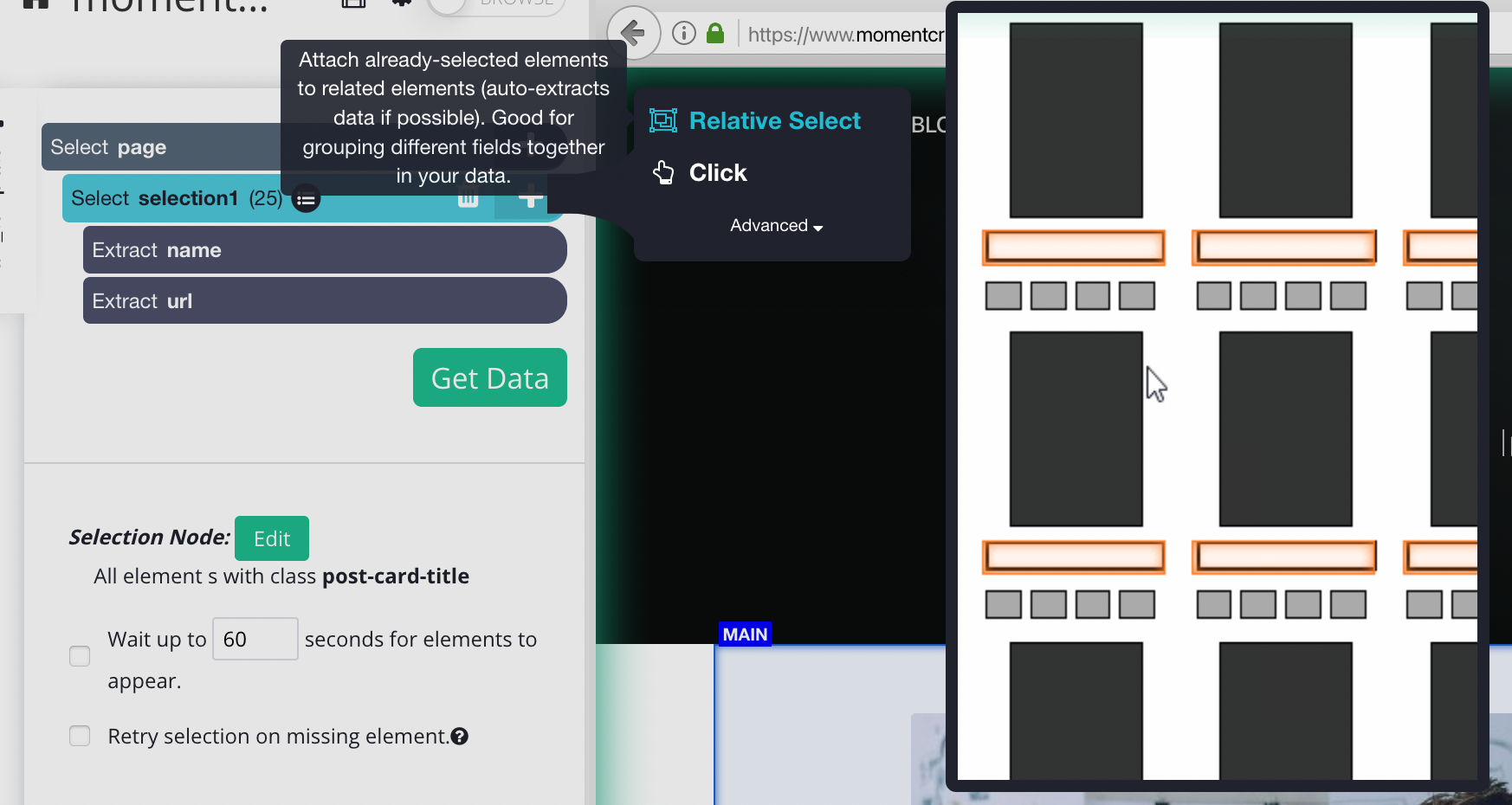
5. Using the Relative Select command, click on the first blog title on the list and then on the date. An arrow will appear to show the association you’re creating. Rename your new selection to “date”

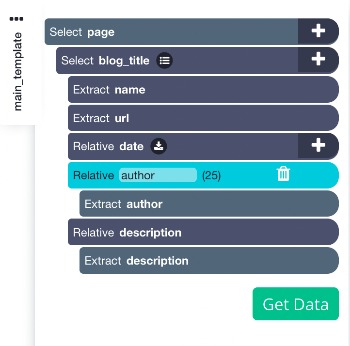
6. You can repeat steps 4-5 to extract additional information like blog author and a quick description. You can choose to scrape the blog image if you choose to.You can expand on the command to remove the extracted url for author and description
Your project should now look like this
Dealing with Infinite Scroll
Since the blog is a scrolling page (scroll to load more) we will need to tell the web scraper to scroll to get all the content.
If you were to run the project now you would only get the first few blogs extracted. So let’s show you how you can deal with a scrolling page
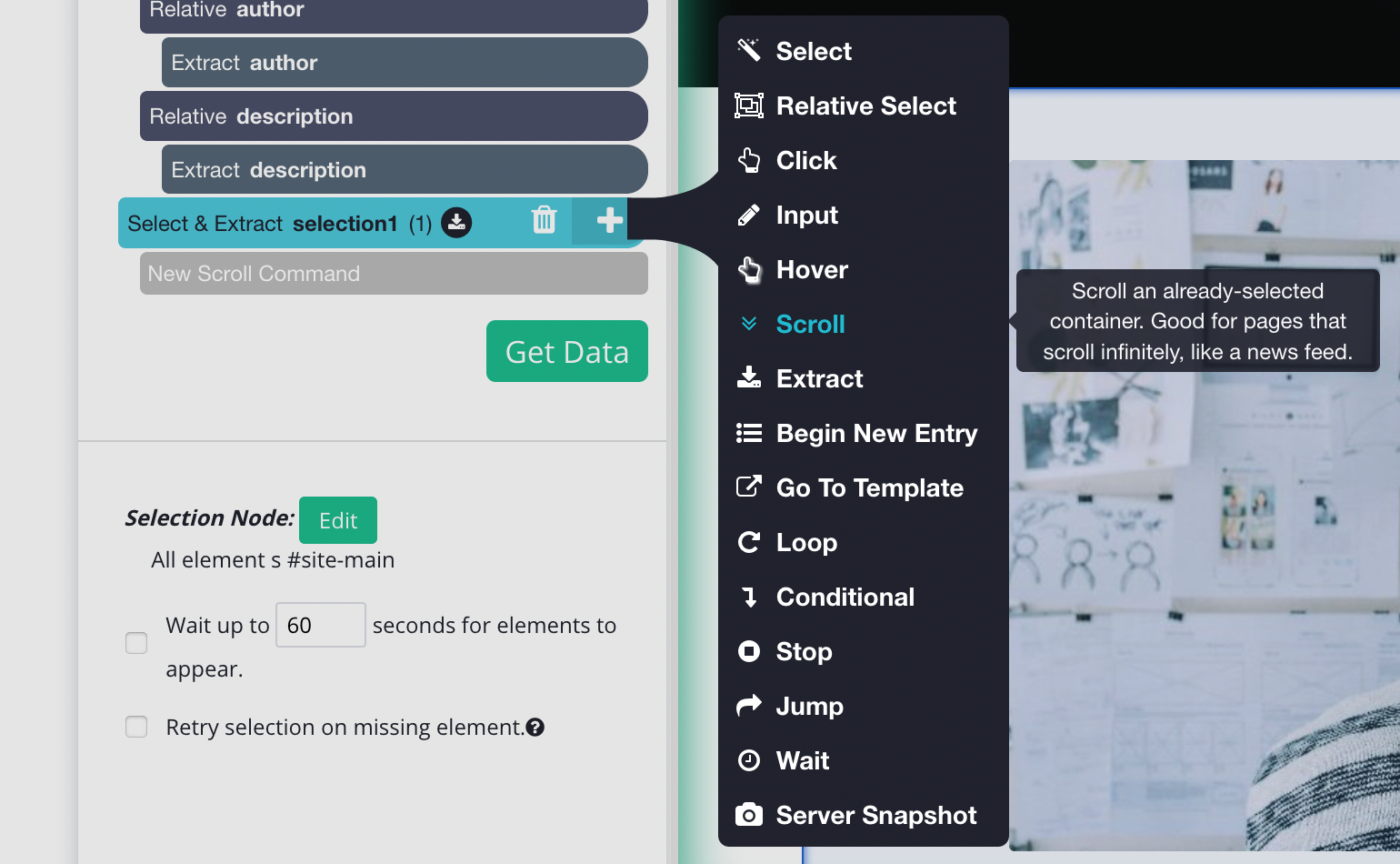
- To do this, click on the PLUS + sign beside the page selection and click select. You will need to select the main element to this, in this case, it will look like this.
2. Once you have the main Div clicked you can add the scroll function. To do this, on the left sidebar, click the PLUS (+) sign next to the main selection, click on advanced, then select the scroll function.
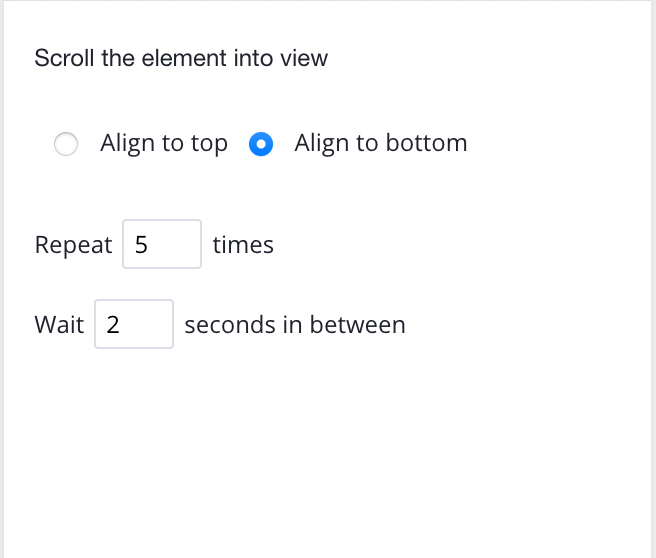
3. You will need to tell how long the software to scroll, depending on how big the blog is you may need a bigger number. But for now, let’s put it 5 times and make sure it's aligned to the bottom.
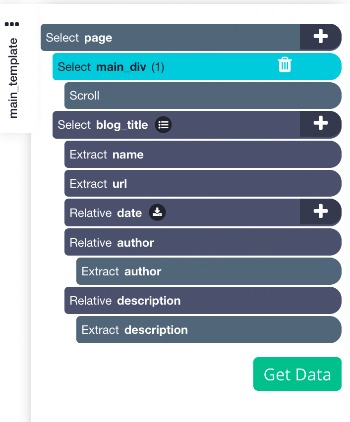
Simply drag your new scroll command and bring it to the top of the page, it should look like this now:
Here are other resources for you to read when dealing with pagination or scroll:
Extracting Blog Headings (optional)
The following steps are optional, if you were to start your web scraping project, you would extract blog title, url, date, author and quick description. This will be more than enough to give you blog content ideas and target keywords.
But we want to extract more information like headings.
Now let’s tell ParseHub to click on each blog title on the page and extract more data like the H2 and h3 tags (the headings).
Note: Adding this will take longer as it scrapes more pages
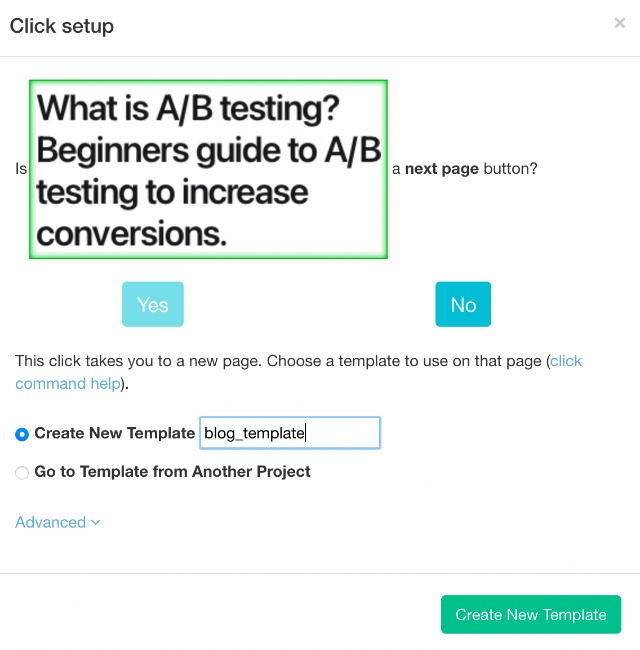
- Start by clicking on the PLUS (+) sign next to your “blog_title” selection and choose the “click” command.

2. A pop up will appear asking you if this is a next page button. Click on no and name your new template to “blog_template” and click on the green “Create New Template” button.
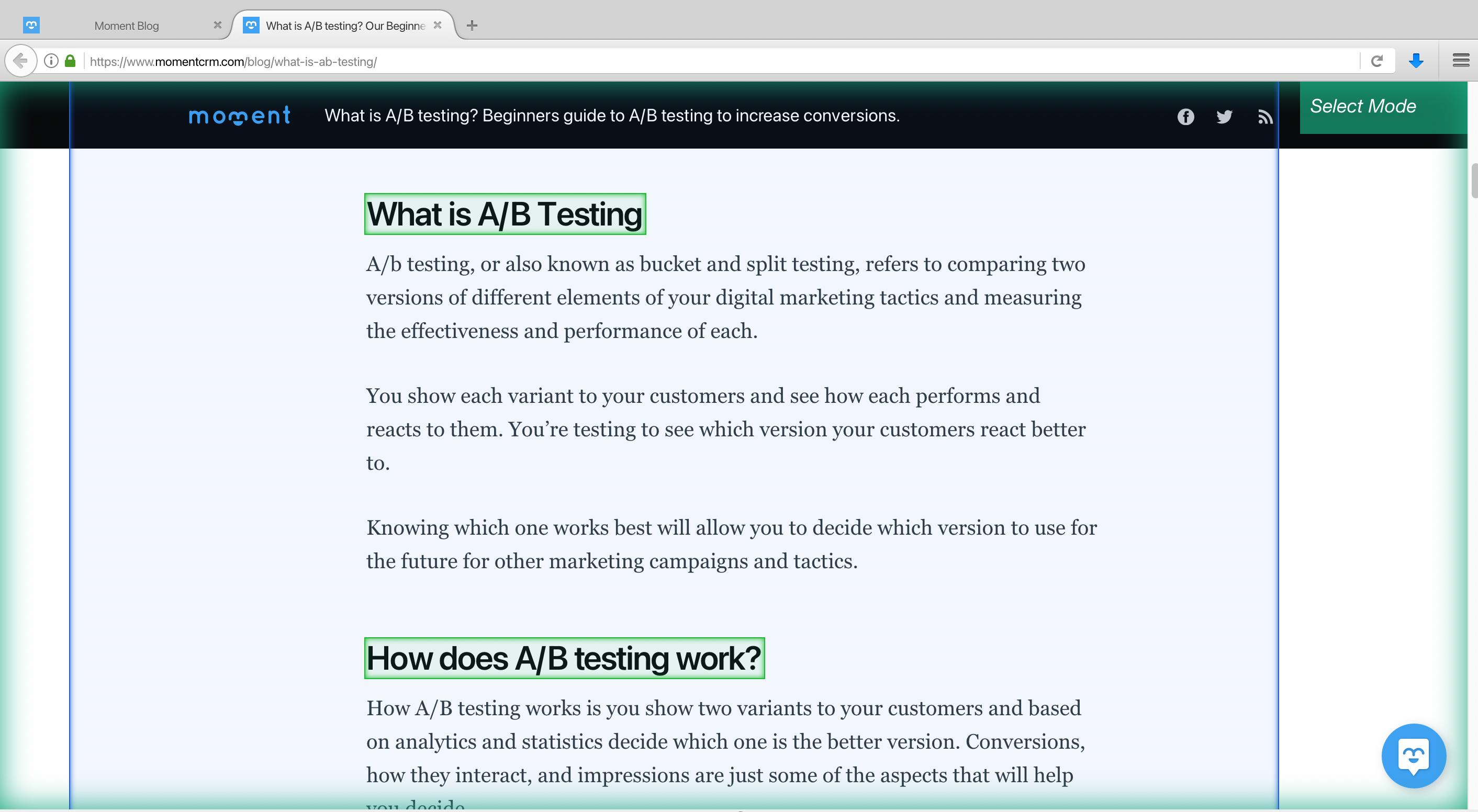
3. The link for the first blog post on the page will now render inside the app and a select command will automatically be created
4. Use this select command to extract any additional data you’d want from this page. In this case, we will extract the first h2 heading. ParseHub will highlight all the other h2 headings in yellow. Click on the next h2 heading that is in yellow to extract all h2 tags
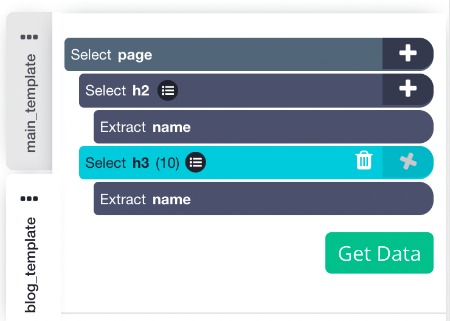
5. To extract more data, click on the PLUS (+) sign next to your “blog_template” selection and choose the Select command. Then use this command to click on more data to extract like any h3 or h4 tags. This is what we have for the "blog_template":
Running your Scrape
It’s now time to run your scrape job and extract all the data you’ve selected.
Start by clicking on the green “Get Data” button on the left sidebar. Here you can Test, Schedule or Run your web scraping project. In this case, we will run it right away.
ParseHub will now go and scrape the data you’ve selected. Once your scrape is completed you will be able to download it as a CSV or JSON file.
Scrape Blog Posts Today!
Now you know how to scrape any competitor’s blogs to help you with your blog content! Just note that you should never completely duplicate any blog of your competitors. However, there’s nothing wrong with using this list to create your own blog posts and have the same targeted keywords as your competitors.
We know projects can get quite complex. If you run into any issues during your project, reach out to us via the live chat on our site and we will be happy to assist you.
Happy Scraping!