
There’s a subreddit for everything.
No matter what your interests are, you will most likely find a subreddit with a thriving community for each of them.
This also means that the information on some subreddits can be quite valuable. Either for marketing analysis, sentimental analysis or just for archival purposes.
Reddit and Web Scraping
Today, we will walk through the process of using a tool for automated web scraping to extract all kinds of information from any subreddit. This includes links, comments, images, usernames and more.
To achieve this, we will use ParseHub, a powerful and free web scraper that can deal with any sort of dynamic website.
Want to learn more about web scraping? Check out our guide on web scraping and what it is used for.
Reddit and Web Scraping
For this example, we will scrape the r/deals subreddit. We will assume that we want to scrape these into a simple spreadsheet for us to analyze.
Additionally, we will scrape using the old reddit layout. Mainly because the layout allows for easier scraping due to how links work on the page.
Getting Started
- Make sure you download and open ParseHub, this will be the web scraper we will use for our project.
- In ParseHub, click on New Project and submit the URL of the subreddit you’d like to scrape. In this case, the r/deals subreddit. Make sure you are using the old.reddit.com version of the site.
Scraping The Subreddit’s Front page
- Once submitted, the URL will render inside ParseHub and you will be able to make your first selection.

- Start by clicking on the title of the first post on the page. It will be highlighted in green to indicate that it has been selected.

- The rest of the post titles on the page will also be highlighted in yellow. Click on the second post title on the page to select them all. They should all now turn green.
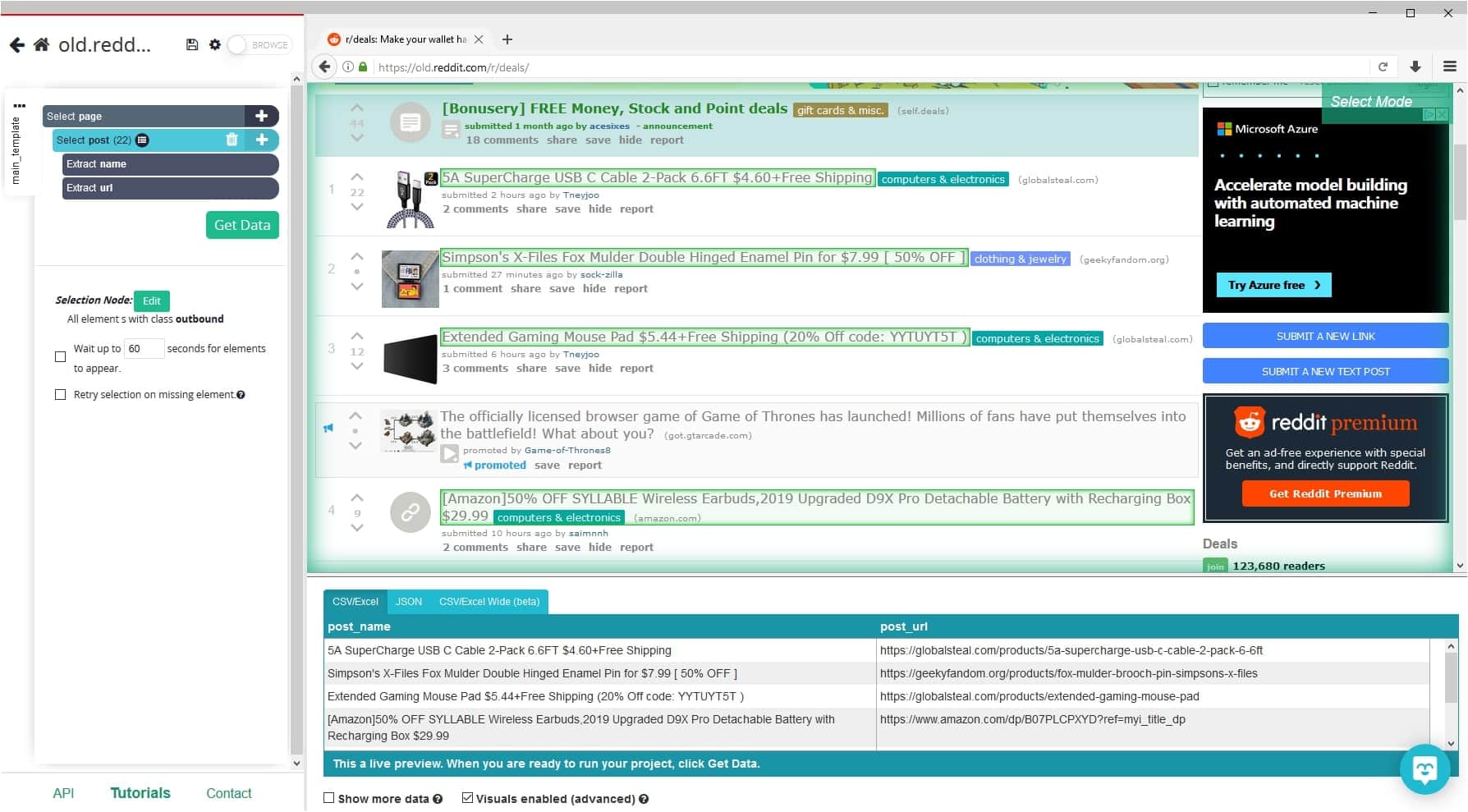
- On the left sidebar, rename your selection to posts. We have now told ParseHub to extract both the title and link URL for every post on the page.
- Now, use the PLUS (+) sign next to the post selection and select the Relative Select command.

- Using Relative Select, click on the title of the first post on the page and then on the timestamp for the post. An arrow will appear to show the selection. Rename this new selection to date.
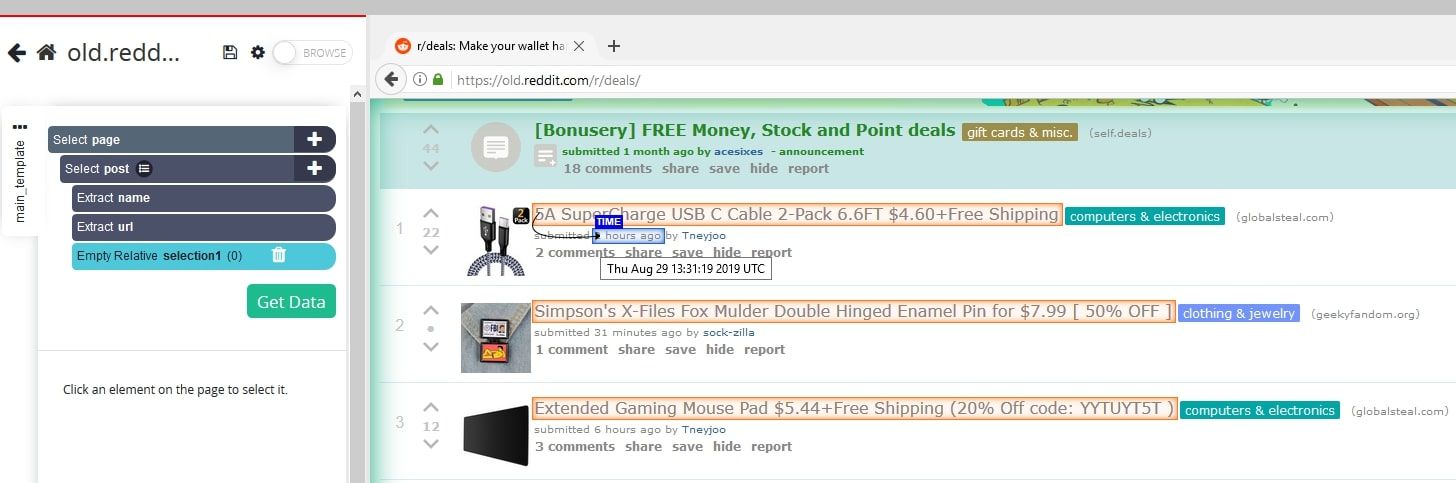
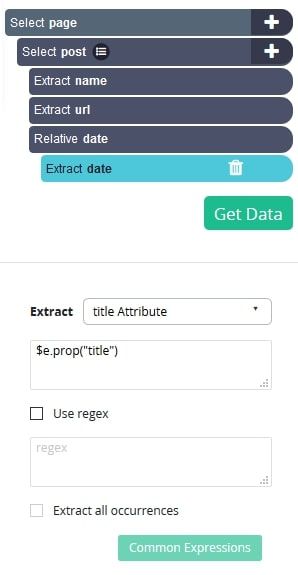
- You will notice that this new selection is pulling the relative timestamp (“2 hours ago”) and not the actual time and date on which the post was made. To change this, go to the left sidebar, expand your date selection and click on the extract command. Here, use the drop down menu to change the extract command to “title Attribute”.
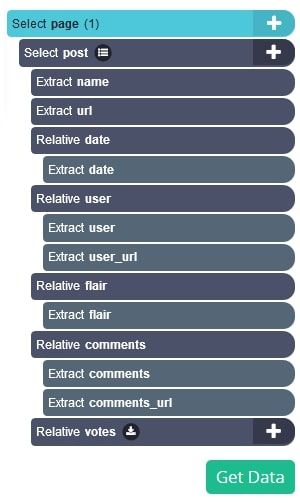
- Now, repeat step 5 to create new Relative Select commands to extract the posts’ usernames, flairs, number of comments and number of votes.
- Your final project should look like this:
Downloading Reddit Images
You might be interested in scraping data from and image-focused subreddit. The method below will be able to extract the URL for each image post.
You can then follow the steps on our guide “How to Scrape and Download images from any Website” to download the images to your hard drive.
Adding Navigation
ParseHub is now setup to scrape the first page of posts of the subreddit we’ve chosen. But we might want to scrape more than just the first page. Now we will tell ParseHub to navigate to the next couple of pages and scrape more posts.
- Click the PLUS(+) sign next to your page selection and choose the Select command.
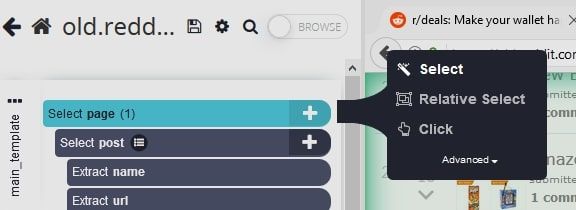
- Using the Select command, click on the “next” link at the bottom of the subreddit page. Rename your selection to next.

- Expand the next selection and remove the 2 Extract commands created by default.
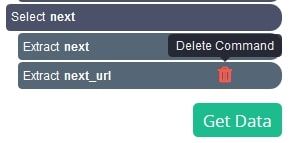
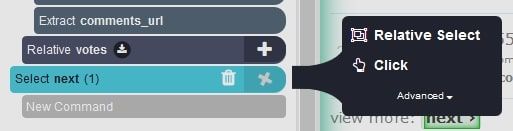
- Now click on the PLUS(+) sign on the next selection and choose the Click command.
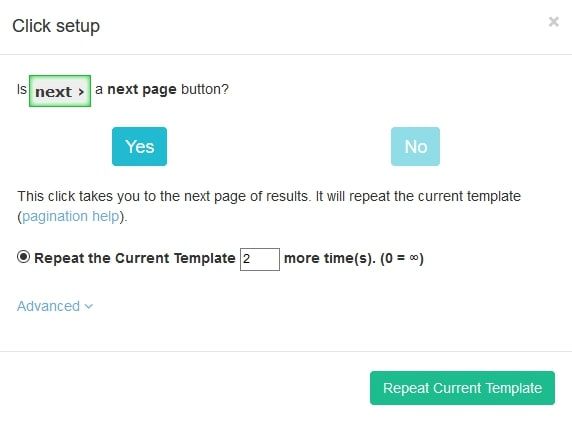
- A pop-up will appear asking you if this a “next page'' button. Click “Yes” and enter the number of times you’d like ParseHub to click on it. In this case, we will input 2, which equals to 3 full pages of posts scraped. Finally, click on “Repeat Current Template” to confirm.
Scraping Reddit Comments
Scraping reddit comments works in a very similar way. First, we will choose a specific posts we’d like to scrape.
In this case, we will choose a thread with a lot of comments. In this case, we will scrape comments from this thread on r/technology which is currently at the top of the subreddit with over 1000 comments.
- First, start a new project on ParseHub and enter the URL you will be scraping comments from. (Note: ParseHub will only be able to scrape comments that are actually displayed on the page).
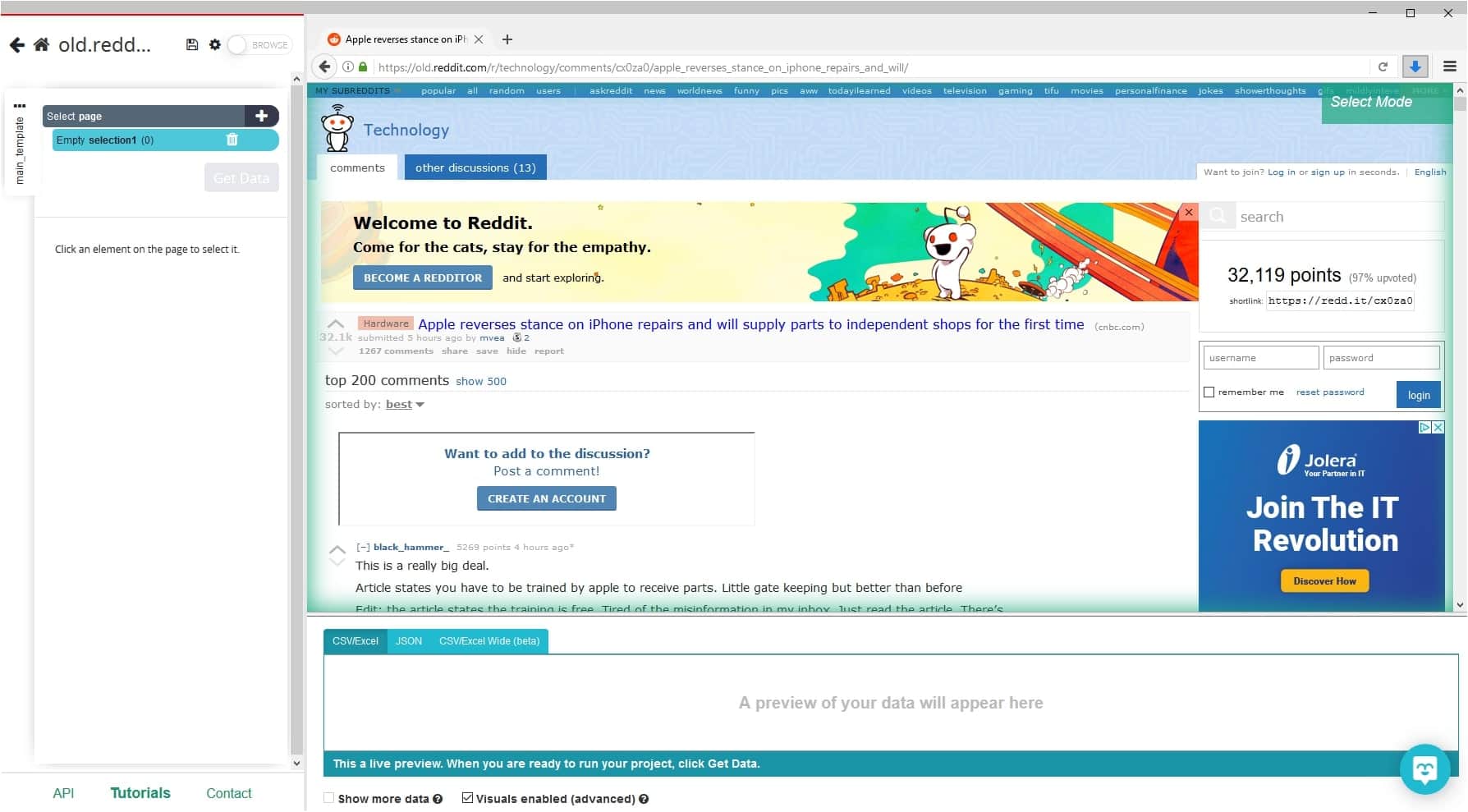
- Once the site is rendered, you can use the Select command to click on the first username from the comment thread. Rename your selection to user.
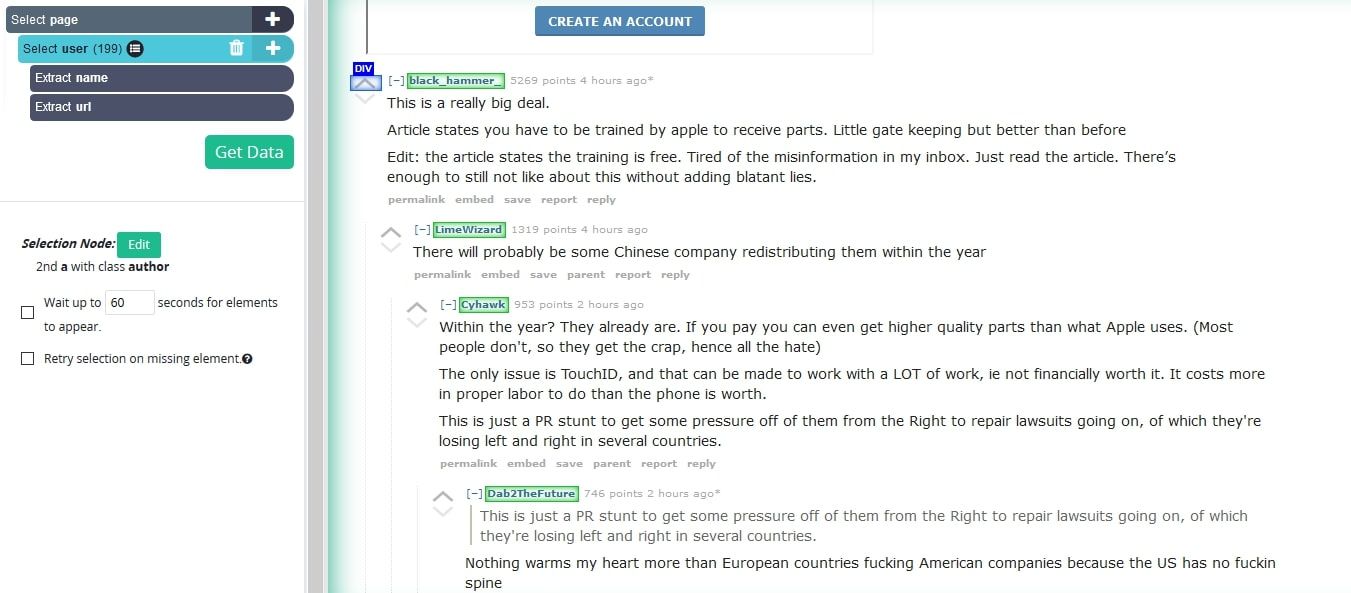
- Click on the PLUS(+) symbol next to the user selection and select the Relative Select command.
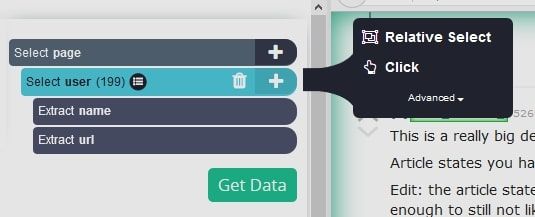
- Similarly to Step 5 in the first section of this post, use Relative Select to extract the comment text, points and date.
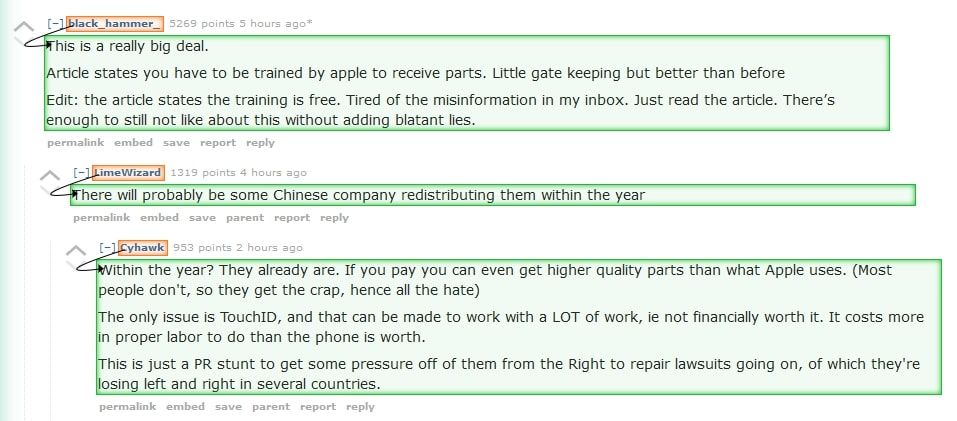
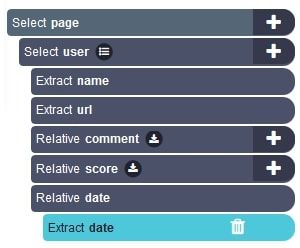
- Your final project should look like this:
Running and Exporting your Project

Once your project is fully setup, it’s time to run your scrape.
Start by clicking on the Get Data button on the left sidebar and then choose “Run”.
Pro Tip: For longer scrape jobs, we recommend running a Test Run first to verify that the data will be extracted correctly.
You will now be able to download the data you’ve scraped from reddit as an excel spreadsheet or a JSON file.
Which subreddit will you scrape first?
Originally published Nov 11, 2019, updated February 26, 2022