
There are many restaurant directories that will have many restaurants listed on its website from different cities.
But how do you accurately and quickly collect this information in a useful format? After all, most of these restaurant directories do not have a simple “export” feature to collect all the business information you might need.
That’s where web scraping comes in! We are ParseHub, and today we’ll show you how you can scrape restaurant data in just a few minutes!
For this project, we will be scraping Zomato and scrape the results for Thai restaurants in Toronto.
If you want to follow along, you can download parsehub for free. The download link is in the description.
Getting started
To get started you’ll need to download and install ParseHub and pay for our standard or professional plan.
For this project, we will be scraping Zomato and scrape the results for Thai restaurants in Toronto. You can use this link if you would like to follow along.
So let’s get started!
Web Scraping restaurant data from Zomato
- In ParseHub, click on New Project and enter the URL we’ve selected. The webpage will now be rendered inside the app.
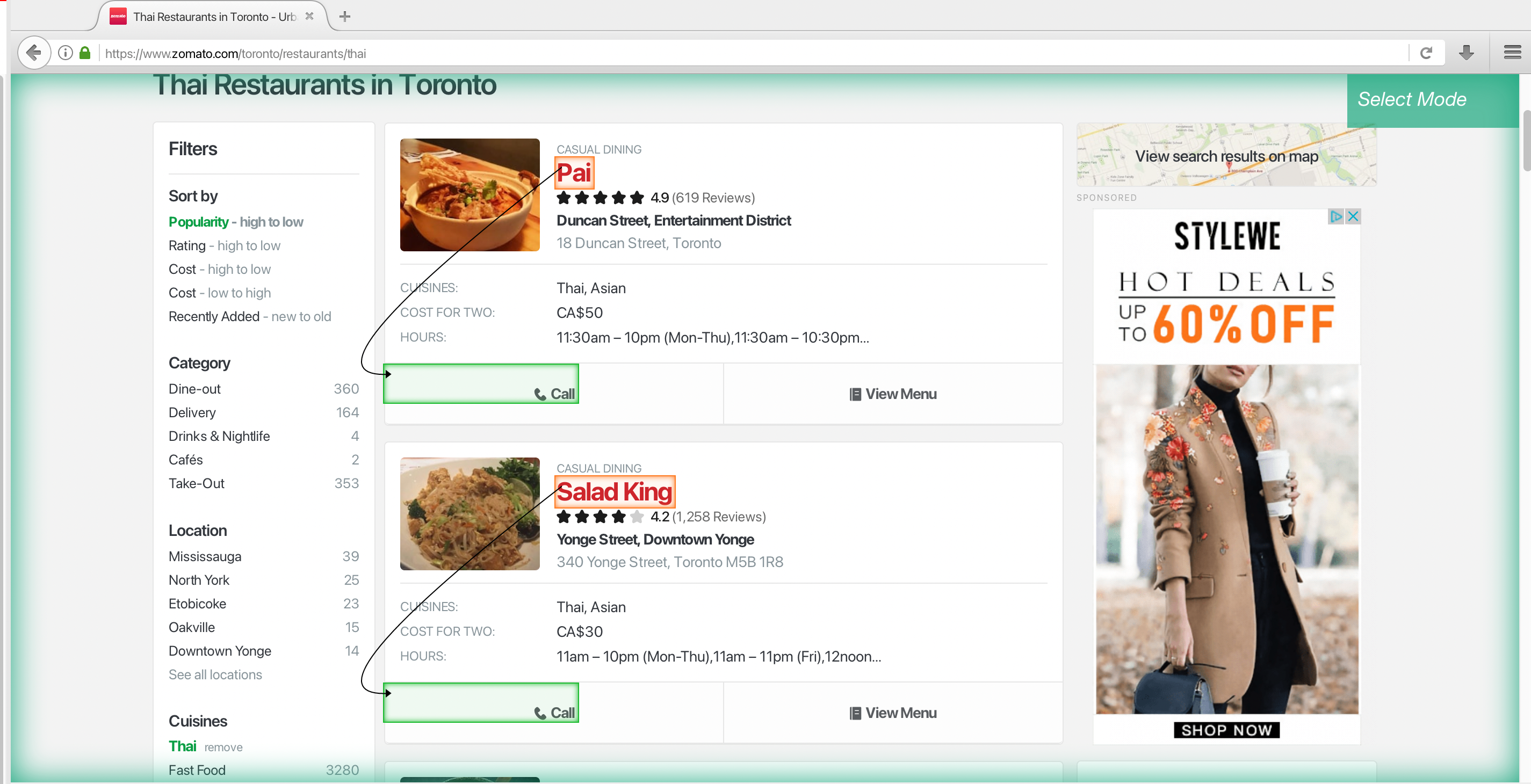
2. After the page is rendered, you will be able to make your first selection. Click on the first restaurant name to select it. It will then turn green to indicate it has been selected.
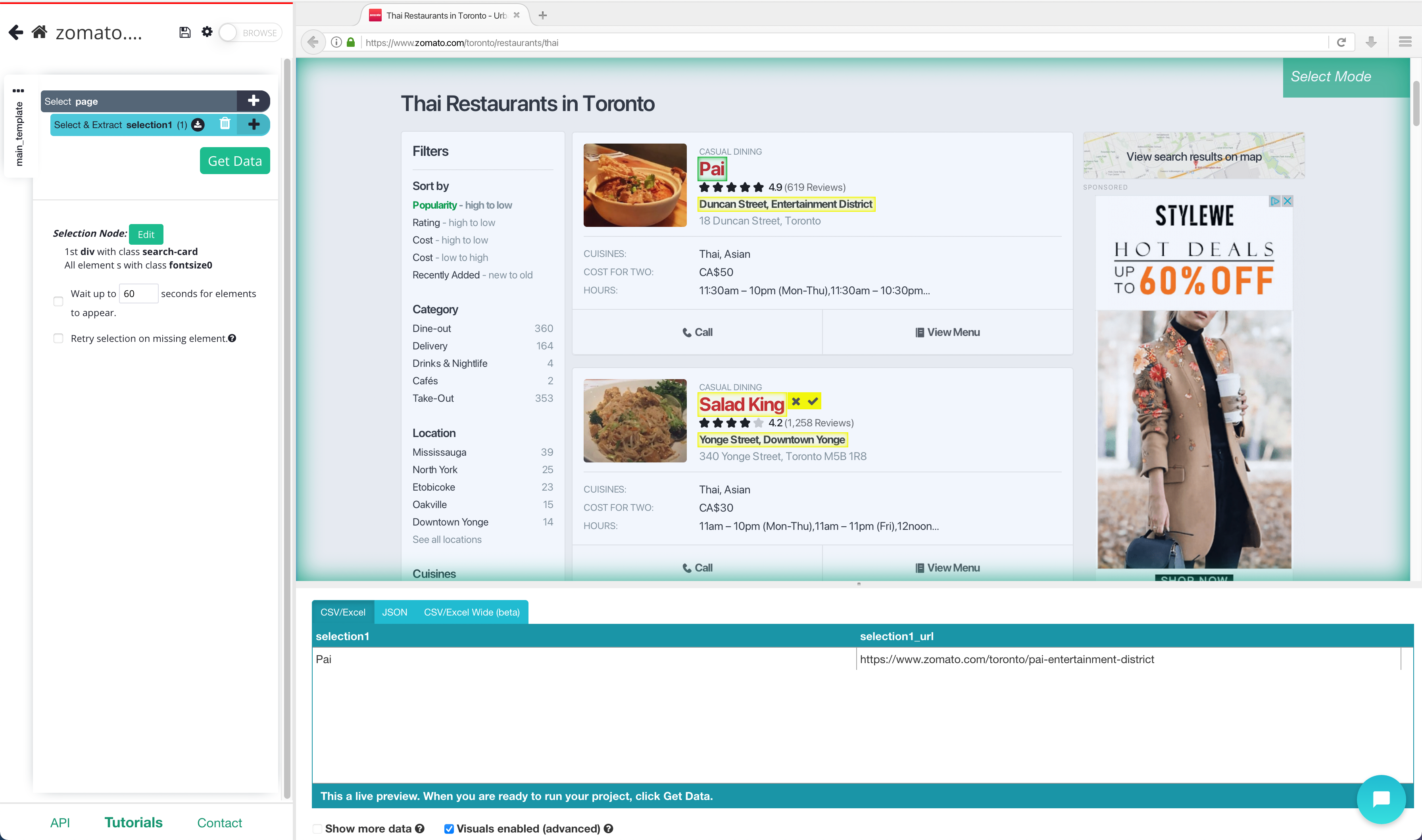
3. The rest of the business names will then turn yellow. Click on the next business name to select all of them. They should all be green now.
4. Now on the left sidebar, rename your selection to Restaurant.

5. Next, click on the PLUS(+) sign next to the business selection and use choose the Relative Select command. Then click on the first business name and then on the address below it (an arrow will appear connecting the two). You may need to do this 2-3 times to fully train ParseHub.
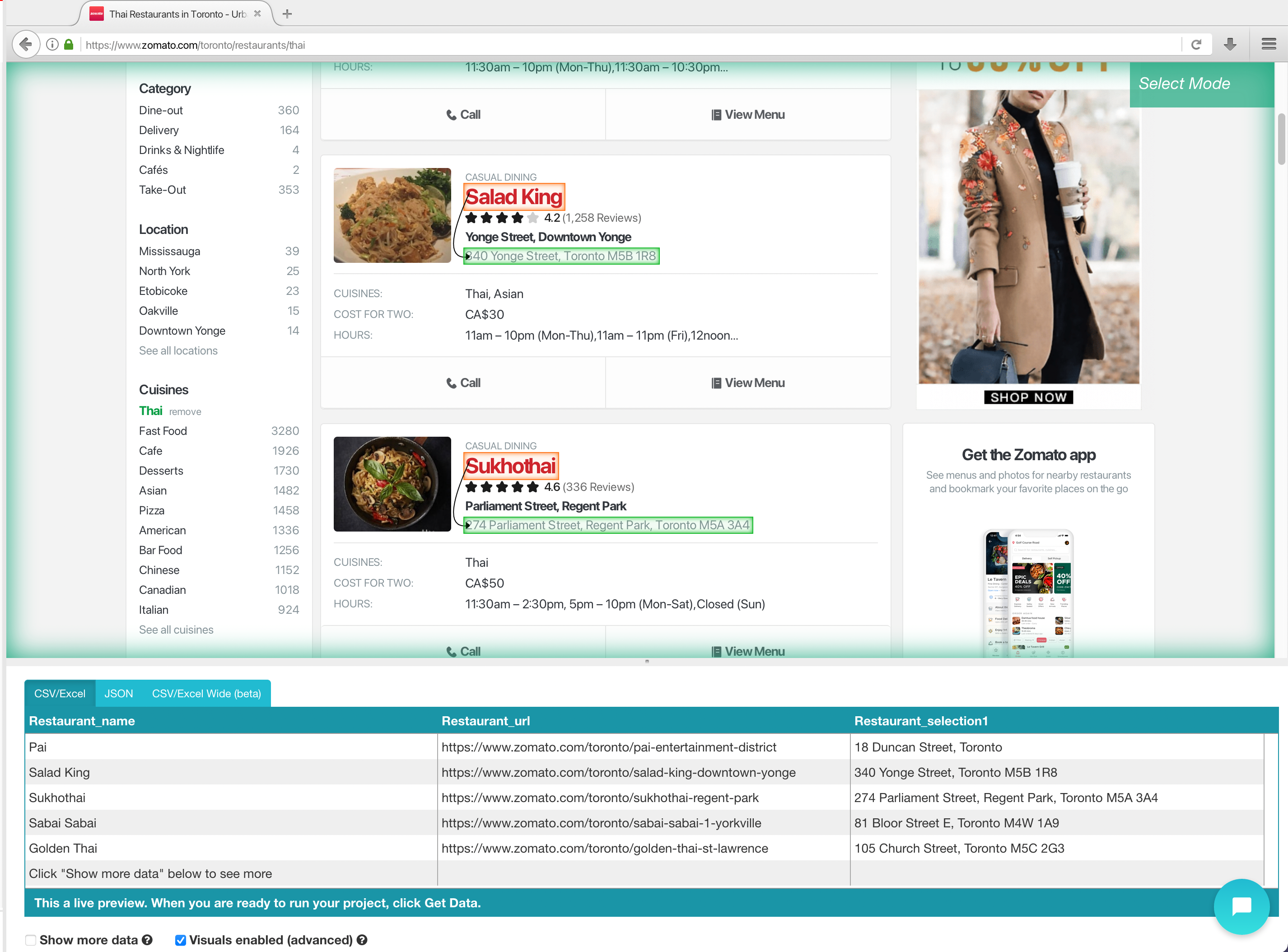
6. Repeat the previous step to also scrape the neighbourhood, rating, and number of reviews
Web scraping data within the HTML Code
Now let’s show you how you can extract data that is within the html code, in this case, we’re going to extract the phone number for each restaurant
- Click on the PLUS(+) sign next to the business selection and use choose the Relative Select command. First click on the first restaurant name, then hover over the call button, and press ctrl or cmd and 1 to zoom out until your selection looks like this.
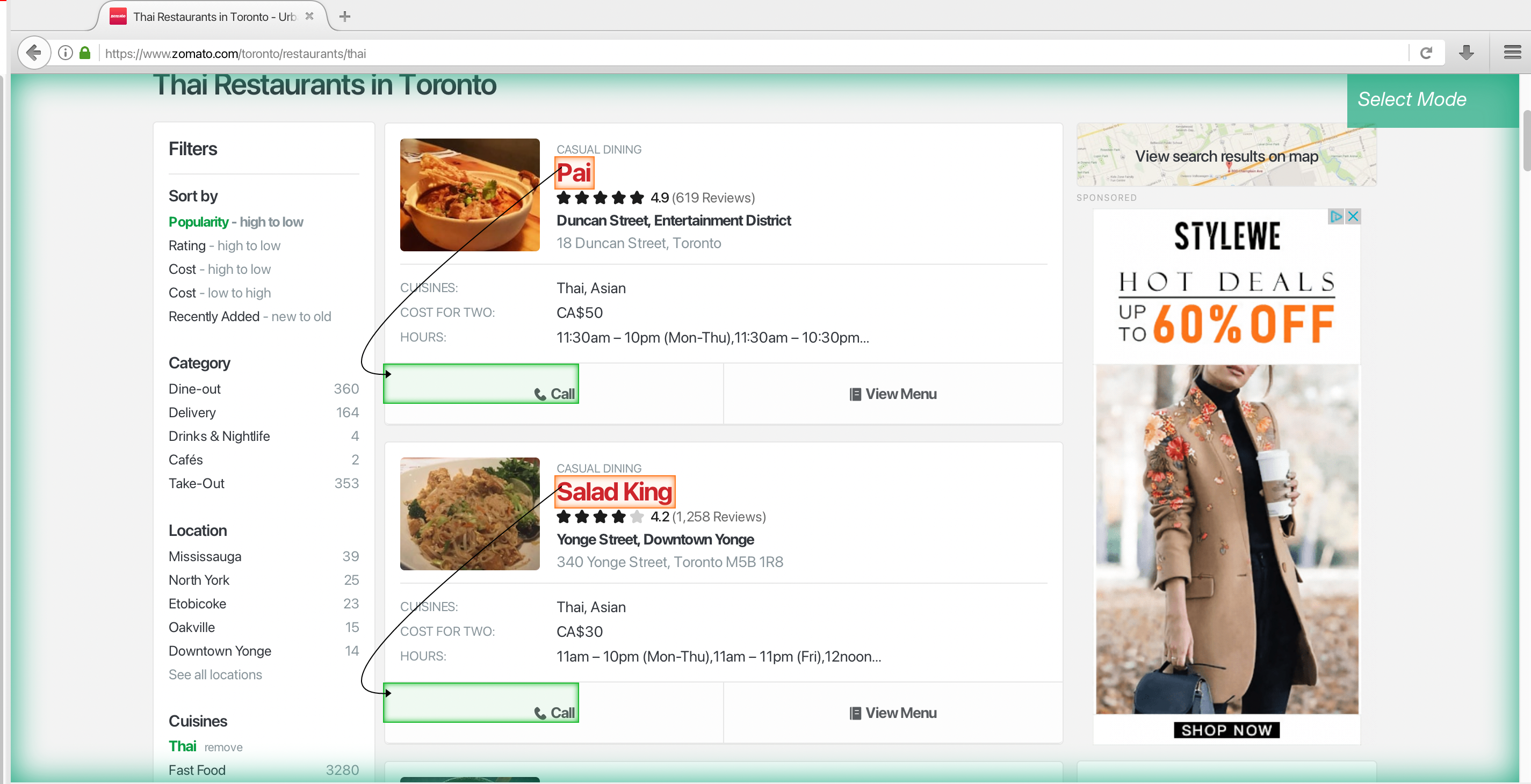
Repeat this step to fully train ParseHub what you want to extract.
2. Rename your new selection to phone_number
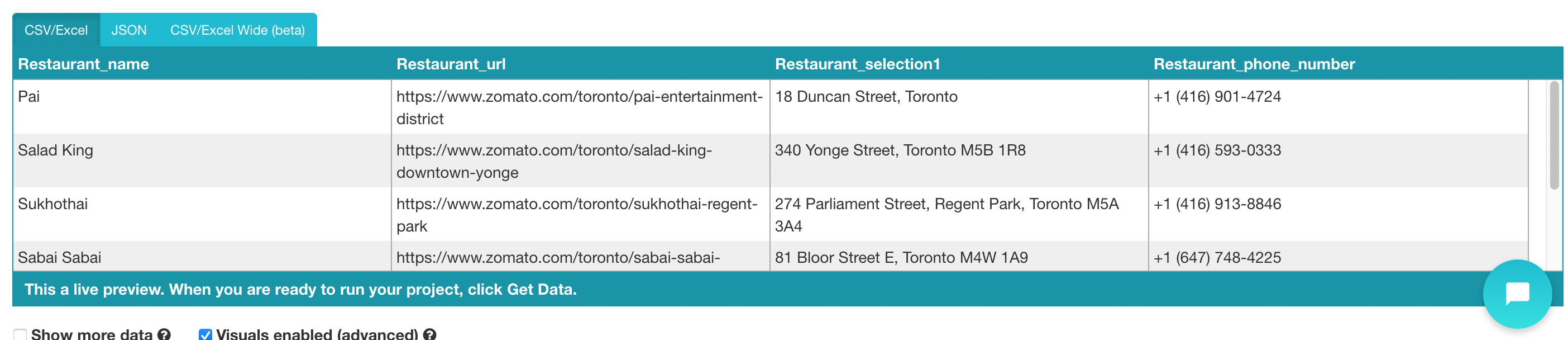
3. Expand your phone number selection, and under the extract command drop-down menu, select the data-phone-no-str attribute.
You should notice that the phone number is now being extracted.
Dealing with Pagination
ParseHub is now ready to scrape the entire first page of results for your keyword. Next, we will instruct it to scrape the next couple of pages of results.
- On the left sidebar, click on the PLUS(+) sign on the page selection. Then use the select command.
- With the select command chosen, click on the “Next” link at the bottom of the Zomato page.

3. By default, ParseHub will extract the link text and URL. We will use the icon next to this selection and remove these 2 items. Feel free to rename the selection to next.
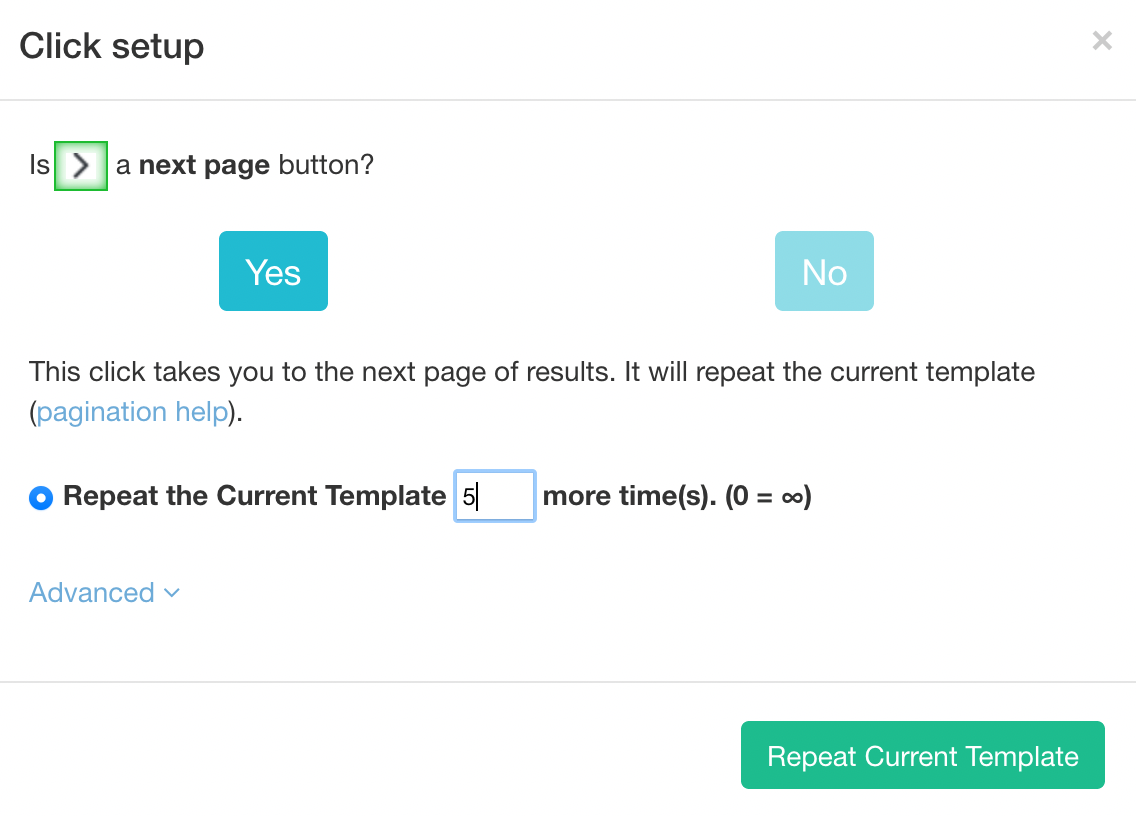
4. Use the PLUS(+) sign next to the next selection and choose the click command.

5. A pop-up will appear asking if this a “Next” button. Click “Yes” and enter the number of times you’d like to click this button. For now, we’ll do 5 to scrape the first 6 pages of results.
Enabling IP Rotation
If you were to run your web scraping project now, your project would come back empty. We’ll quickly show you how to enable IP Rotation.
Note: IP rotation is a paid feature. If you do enable IP rotation, your project will take longer to complete.
- Click on the gear icon, and then select settings
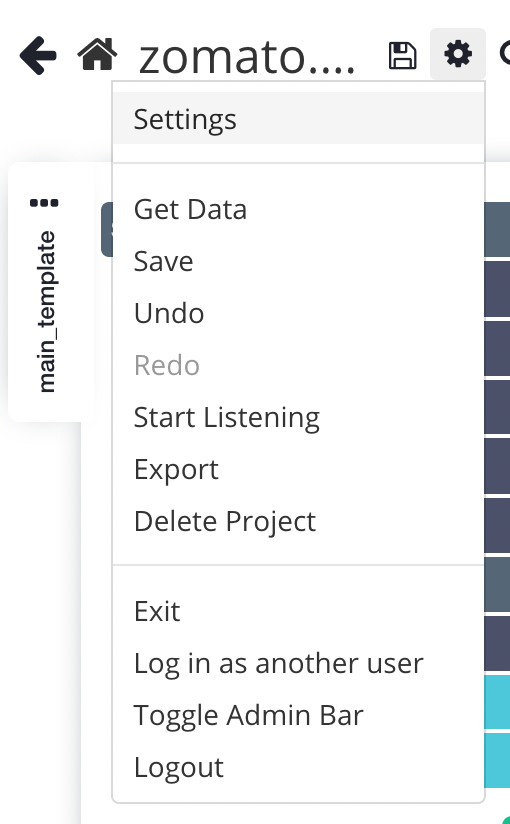
2. Click on Rotate IP address
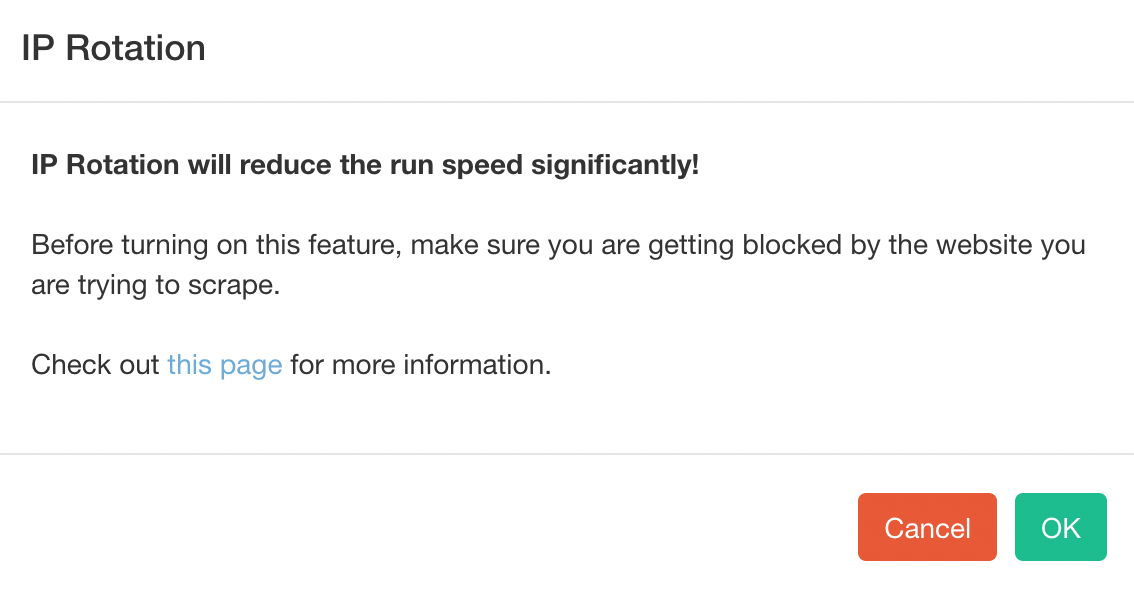
3. A Popup will appear with to warning about your run speed, click on OK
Now you’re ready to begin your web scraping project!
Running your scrape
Now that you’re done setting up your scraping project, it’s time to run it!
Use the Get Data button on the left sidebar and click on Run to start your scraping job. Depending on how many pages you’ve chosen, the time for it to be completed will vary.
Pro Tip: For longer time-consuming jobs, always do a Test Run first. You might not want to wait for your file to come out and not be formatted in the way you want it.
Once your scrape is completed, you will be able to download it as an excel sheet or a JSON file.
Closing Thoughts
Now you know how to scrape a website without getting blocked. This paid feature comes in handy as it will allow you to scrape websites without getting your IP address banned from or getting blocked.
We understand that web scraping projects can get quite complicated. If you have any trouble, you can contact our customer support team using our live chat where we’ll be more than happy to assist you!
Happy scrapping