
Wikipedia is, without a doubt, one of the web’s largest resources for all knowledge.
The site houses all kinds of information. From expansive topics such as politics, science, technology, and history to more mundane knowledge, such as a detailed history of the spoon.
The best part of it all, is that Wikipedia offers all this information for free. In fact, you can download the entire Wikipedia database if you’d like. It doesn’t get much better than that.
However, you might not want to download entire databases and articles. Or perhaps, you might want to extract data from Wikipedia in a more convenient format, such as an Excel spreadsheet.
Here’s where web scraping can help.
Wikipedia and Web Scraping
With the help of a web scraper, you would be able to select the specific data you’d like to scrape from an article into a spreadsheet. No need to download the entire article.
Taking it a step further, you can set up a web scraper to pull specific information from one article and then pull the same information from other articles.
To showcase this, we will setup a web scraper to extract the standings for every single Premier League season from Wikipedia.
We will also use ParseHub, a free and powerful web scraper which will allow us to easily complete this task.
Scraping a Wikipedia Article
Before starting, we’ll need to complete the following steps.
- Grab the URL of the article you will scrape first. In this case, we will start with the article for the first season of the Premier League in 1992-1993.
- Next, we will download and install ParseHub for free to scrape the data we want.
Now with ParseHub open and ready to go, we will start our project.
- In ParseHub, click on New Project and submit the URL to scrape. ParseHub will now render the page inside the app.
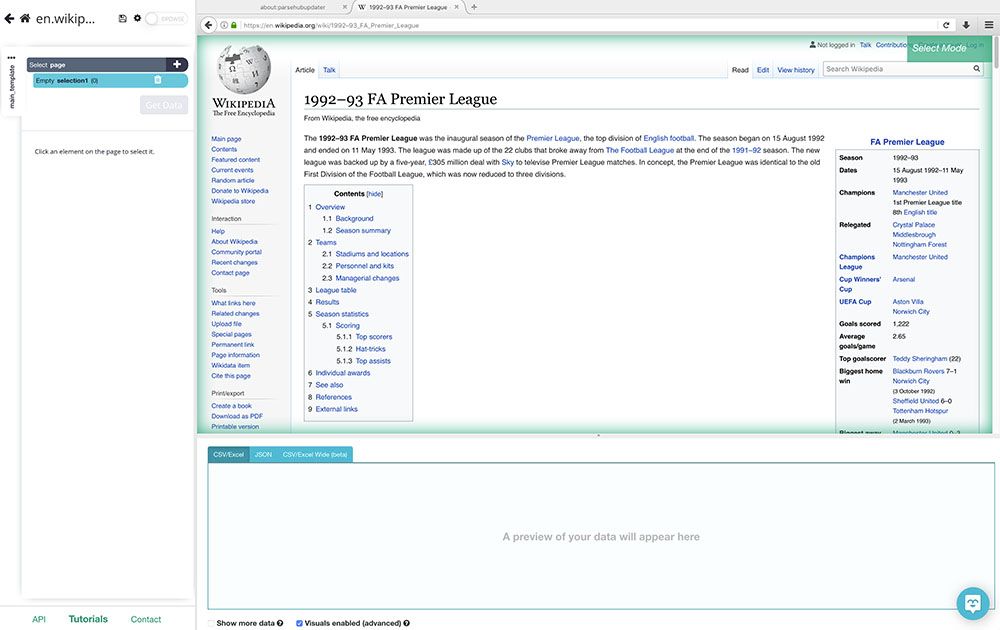
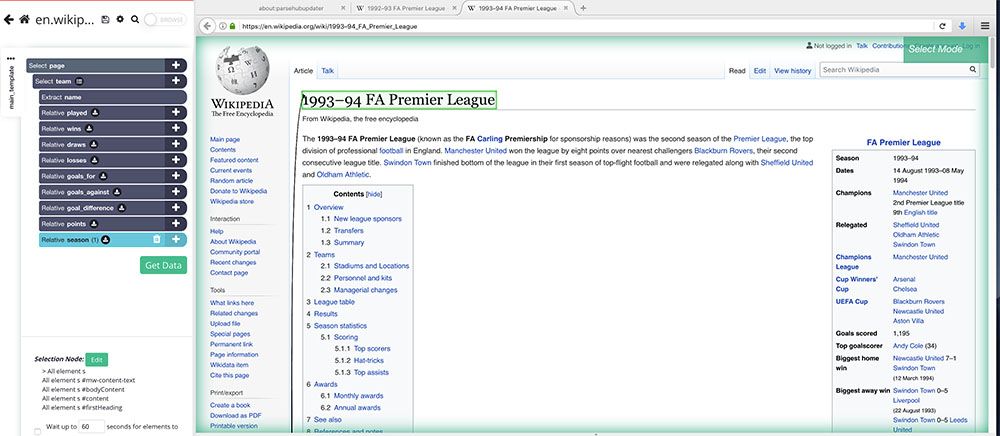
- Our first selection will be the teams from each season and their scores. Scroll down to the League Table section of the article and click on the first team on the table (in this case, Manchester United). The team’s name will turn green to indicate that it has been selected.
- The rest of the team names will be highlighted in Yellow, click on the second one on the list (in this case, Aston Villa) to select them all.
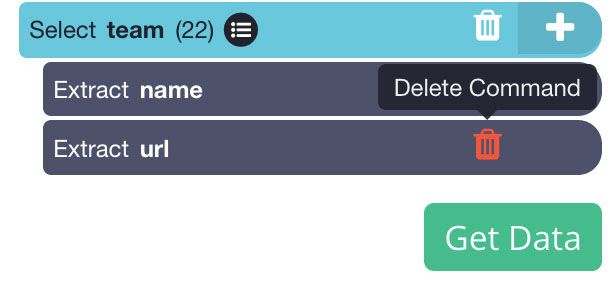
- In the left sidebar, rename your new selection to team. You will notice that ParseHub is extracting the name of each team plus the URL of their articles. In this case, we will remove the article URL since we do not need it. Do this by clicking on the trash can next to the extraction.
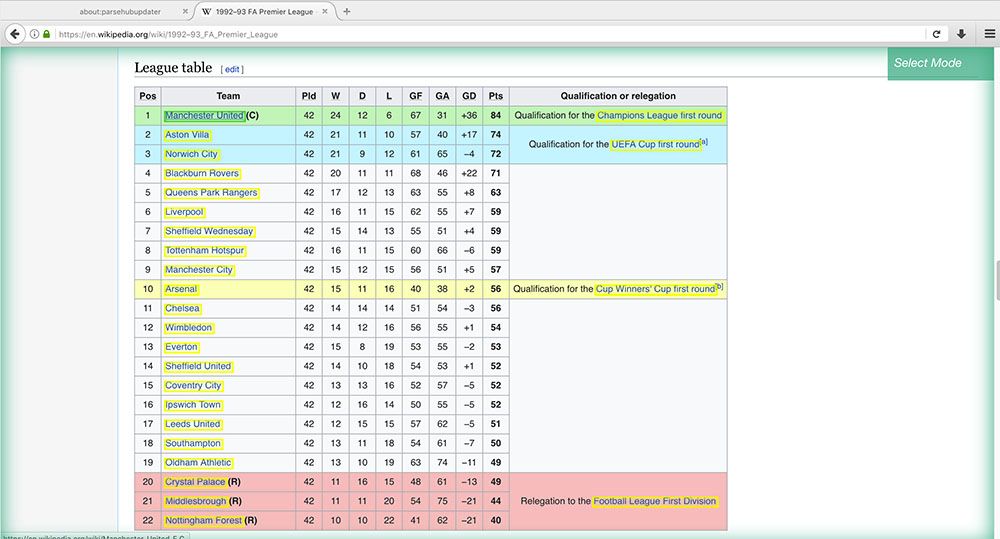
- Now we will extract every column in the table. (Note: The tables on all Premier League wikipedia articles are formatted in the same exact way. If tables from each page were to be formatted differently, it might break your scrape.)
- Start by clicking on the PLUS(+) sign next to your team selection and choose the Relative Select command.

- Using the Relative Select command, click on the name of the first team and then on the number right beside them. In this case, that’s the number of matches played. An arrow will appear to indicate the association you have created.
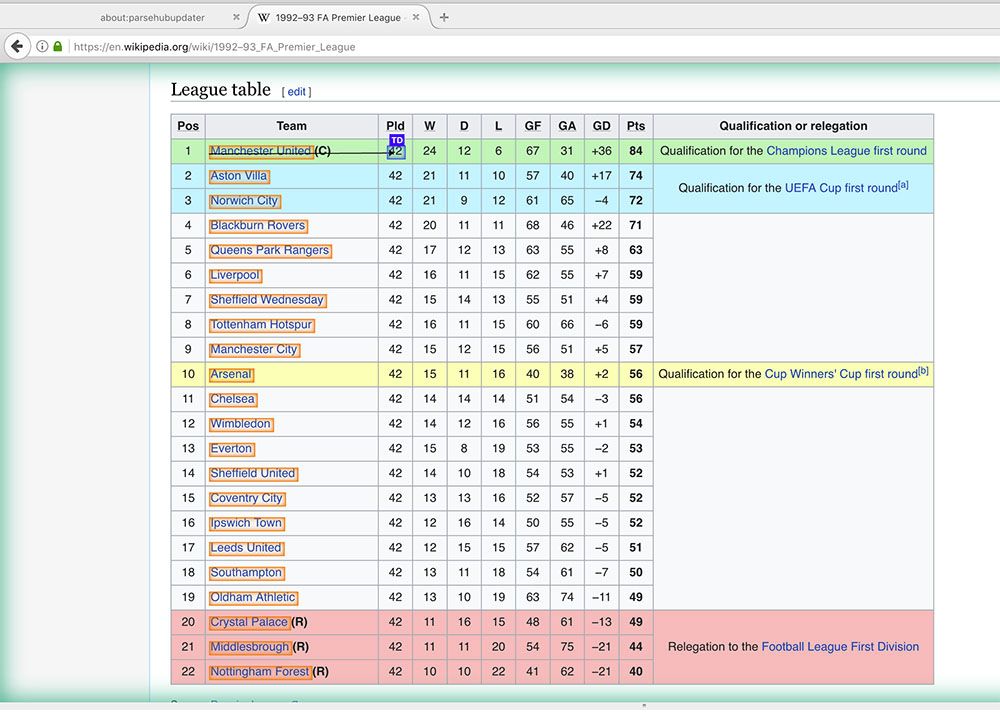
- Rename your selection to played.
- Repeat steps 6 to 8 to pull data for every column on the table (except for the “Qualification or Relegation” column). Make sure to rename your selections accordingly.
- Now, create one last Relative Select command under the team selection. Use it to click on the first team on the table and then on the title of the entire article (in this case, “1993-94 FA Premier League”). Rename this selection to season. This will allow us to know which season the data we extracted is from.
Dealing with Paginated Articles
We will now tell ParseHub to scrape the same data for every year of the league. Luckily, this is quite easy to set up.
- Start by clicking on the PLUS(+) sign next to the page selection and choose the Select command.
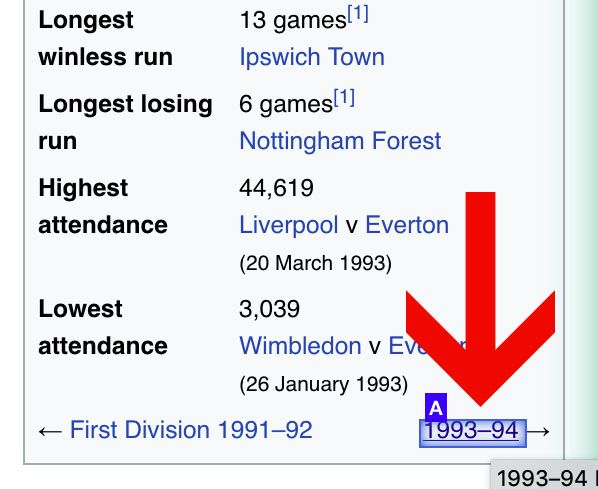
- Using the select command, find the link to the next chronological article and select it. In this case, the link is at the bottom of the info box at the beginning of the article.
- Rename your new selection to next. Expand it using the icon next to it and remove both extract commands from it.
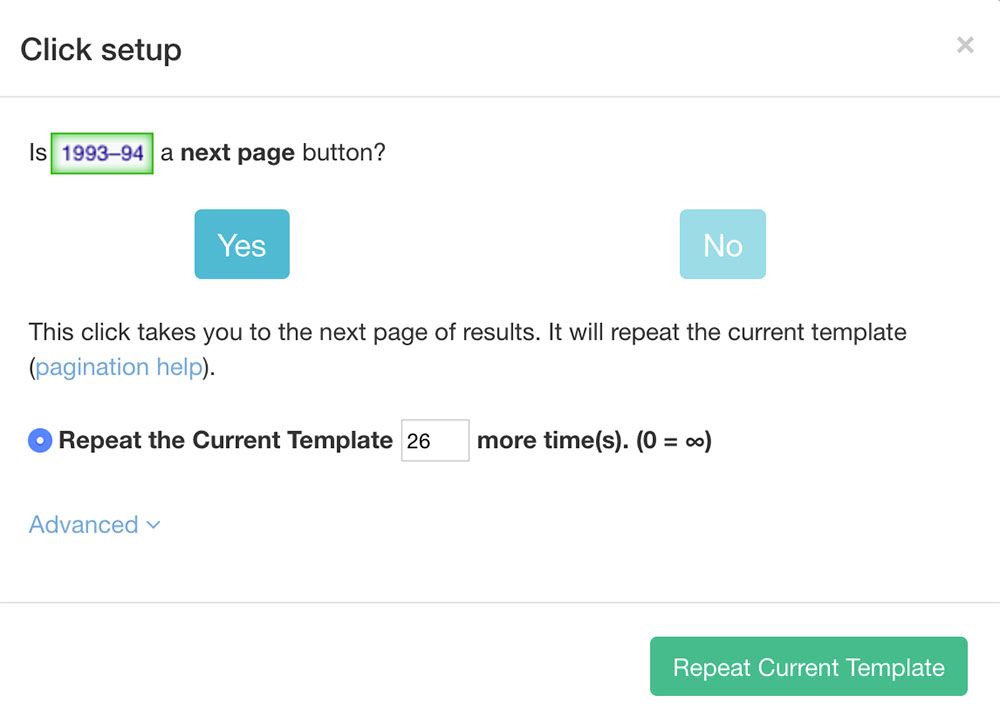
- Now use the PLUS(+) sign next to your next selection and choose the Click command.
- A pop-up will appear asking you if this a “next page” link. Click Yes and enter the number of times you’d like to repeat this process. In this case, we will repeat it 26 times. Click on the “Repeat Current Template” button to confirm.
Running your Scrape
You are now ready to run your scrape. On the left sidebar, click on the green “Get Data” button.
Here, you can run your scrape, test it or schedule it for later.
Pro-Tip: For larger scrape jobs, we recommend to always test your scrapes before running them. In this case, we will just run it right away.
ParseHub will now collect all the data you’ve selected and notify you once the scrape is complete. You will then be able to download it as an Excel spreadsheet or JSON file.
Closing Thoughts
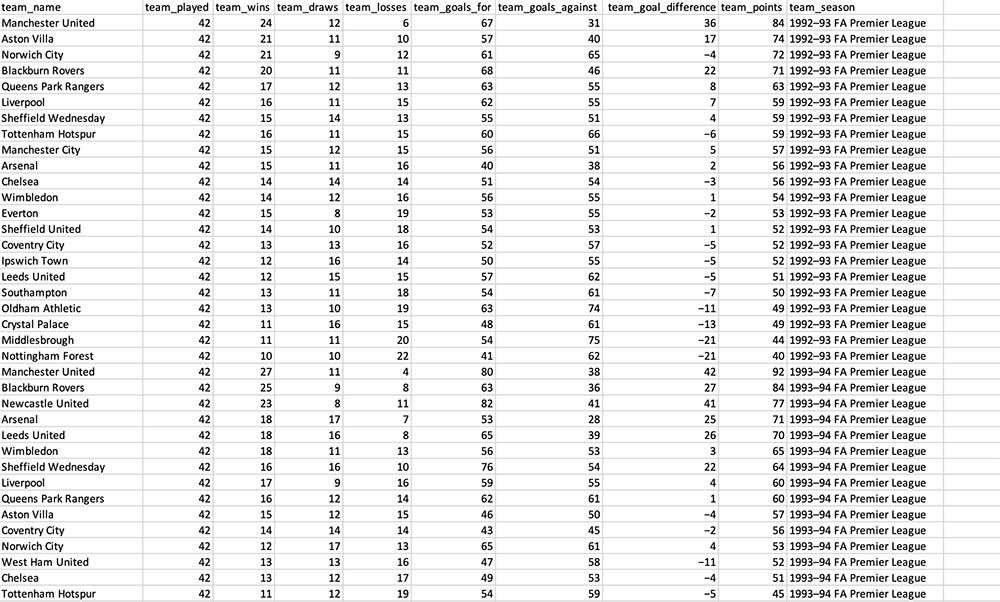
And that’s all there is to it. You are now free to use the dataset you’ve scraped for further analysis.
In our case, we used this dataset to put together a bar chart race that ranks the Premier League teams over time:
However, we know that Wikipedia articles come in many different shapes and sizes. If you need help with your web scraping project, reach out hello(at)parsehub.com for support.
What will you use your new web scraping skills for?