
Almost every website on the internet is written using HTML.
If you’d want to automatically extract data from a website, you would have to deal with a bunch of HTML code.
A web scraper can help you extract data from any site and also pull any specific HTML attributes such as class and title tags. Web scrapers are used to scrape anything from prices, descriptions, statistics and even code, which we will show you shortly.
Using a Web Scraper for HTML Scraping
For our example, we will be using ParseHub, a free and powerful web scraper.
One specific feature that will help us with this project, is ParseHub’s ability to also pull HTML code and attributes from a website rather than just the text on the page.
Aside from scraping HTML code, ParseHub can also help you scrape data from any website into an Excel spreadsheet!
Also, for this example, we will scrape the first page of Amazon results for the term “smartphone”.
Setting up a Web Scraping Project
To begin, you will have to download and install ParseHub for free. Once open, click on New Project and submit the URL we will be scraping.
ParseHub will now render the page and you will be able to select the data you’d like to extract.
Selecting and Extracting Data
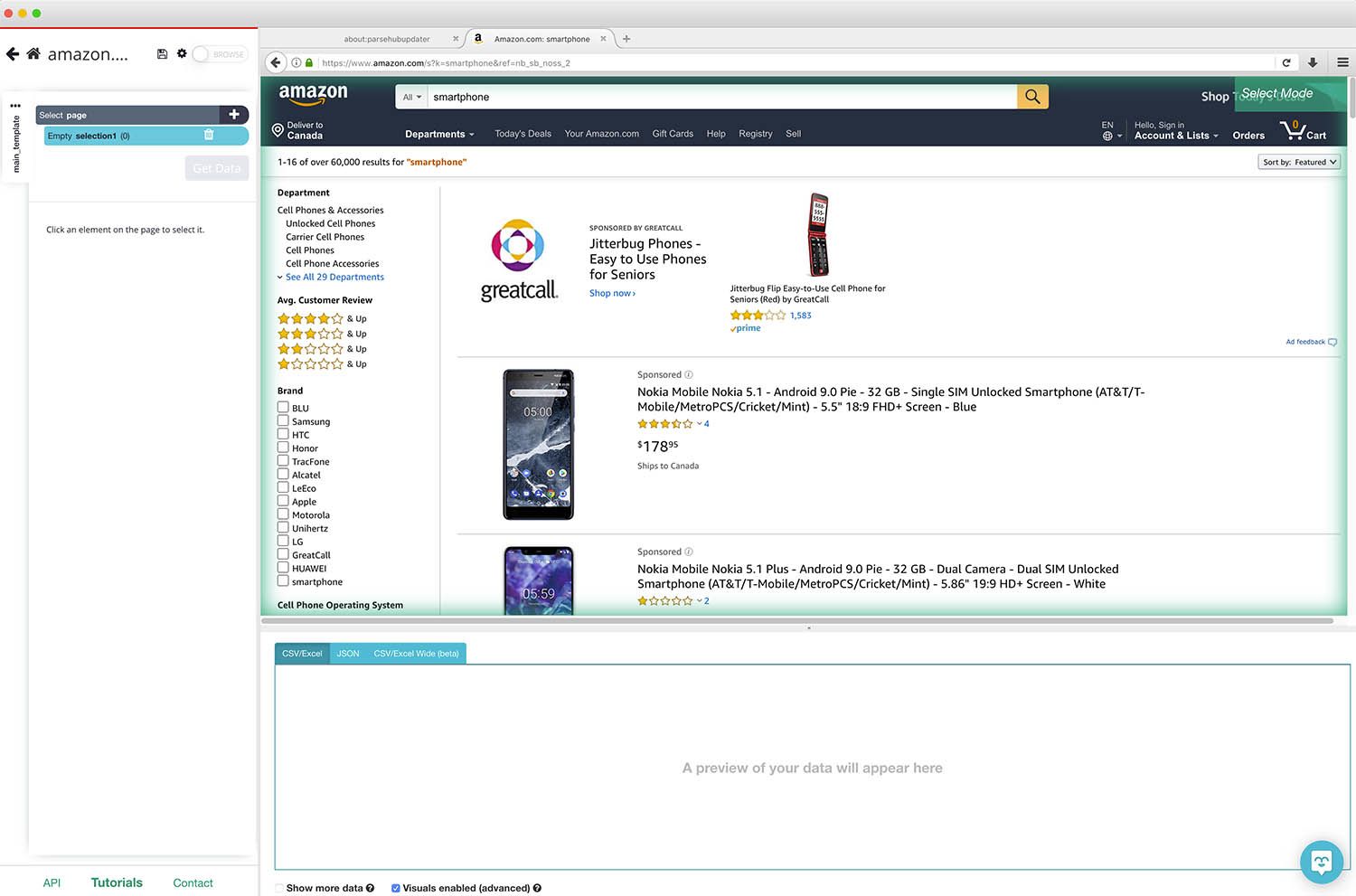
- Once you’ve submitted the URL, scroll down to the first organic (not sponsored) result on the page and click on the title of the first product on the page. It will be highlighted in green to indicate that it has been selected.
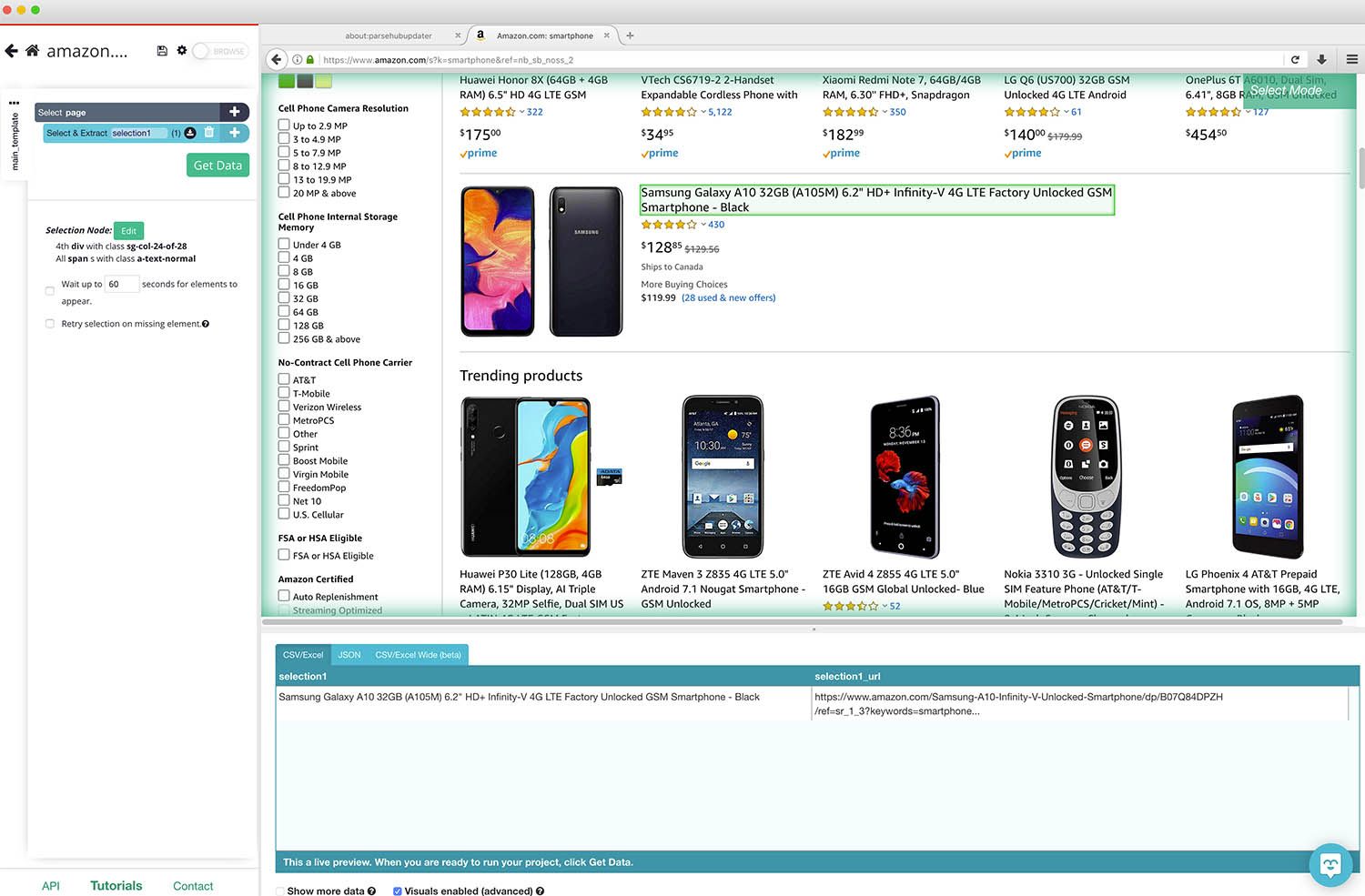
- The rest of the products on the page will be highlighted in Yellow. Click on the second result of the page to select them all (they will now be highlighted in green).
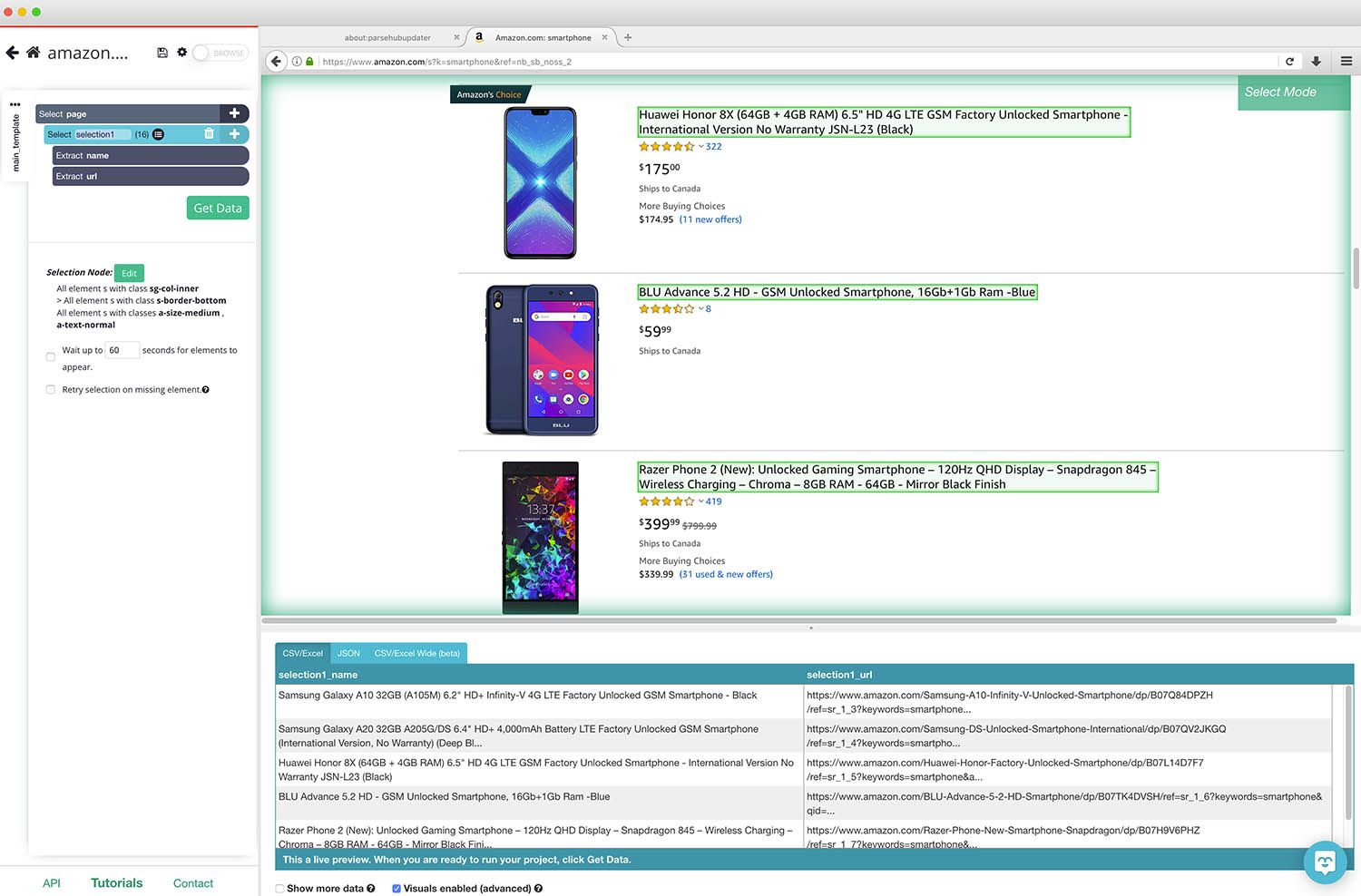
- ParseHub is now extracting the name and URL for each product on the page, since these are present in the element we have selected.
- On the left sidebar, we can rename our selection to product.
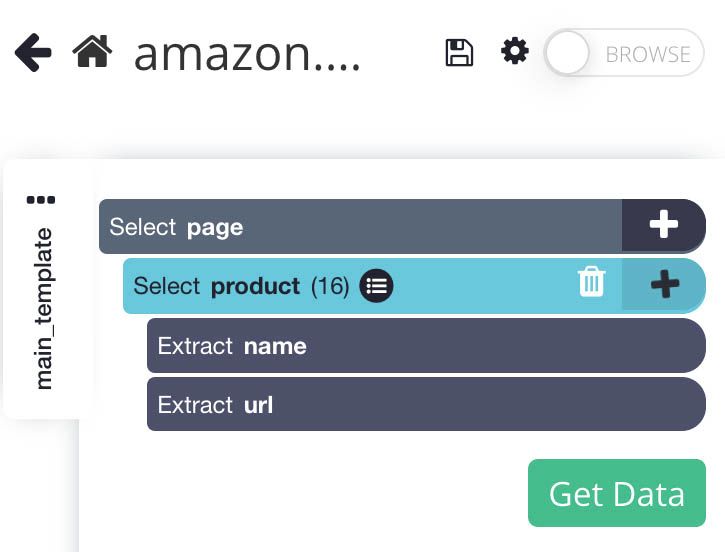
Now that we have selected some data to extract, we will be able to pull additional data from the HTML code in our selection.
Extracting HTML Data
Once you’ve selected some data to extract, you can now select each extraction on the left sidebar. In our example, we have two extractions: one for the product name and one for the listing URL.
You can now select the extractions and use the dropdown to edit them and extract specific HTML elements.
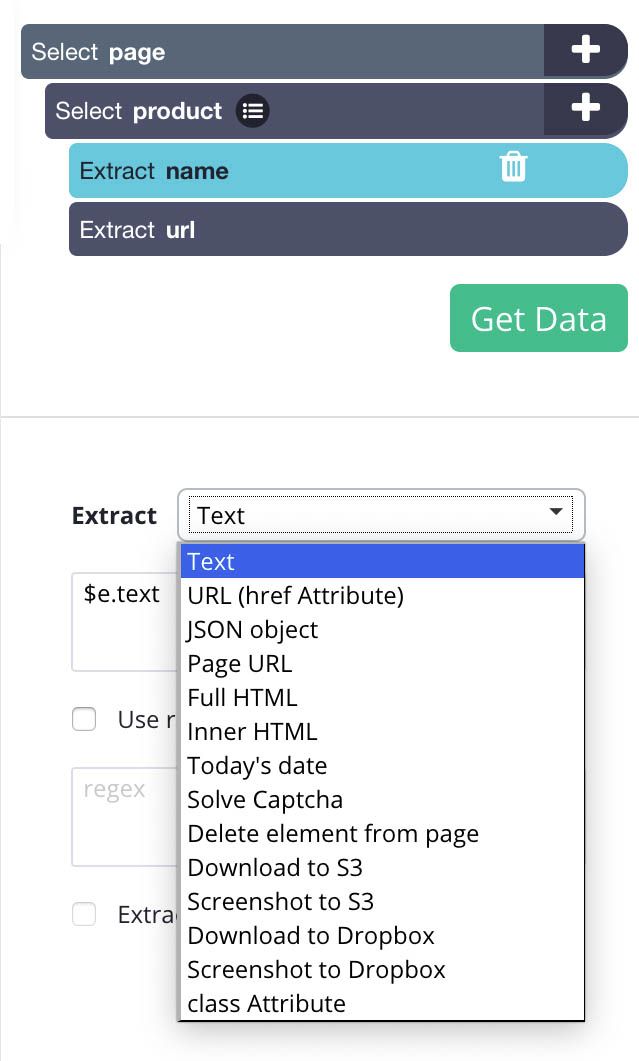
By default, the extraction will first extract the text that has been selected.
Extraction: Text
Result: Samsung Galaxy A10 32GB (A105M) 6.2" HD+ Infinity-V 4G LTE Factory Unlocked GSM Smartphone - Black
Next, we can also extract the href Attribute for our selection (URL).
Extraction: URL (href Attribute)
Result: https://www.amazon.com/Samsung-A10-Infinity-V-Unlocked-Smartphone/dp/B07Q84DPZH/
The Full HTML extraction will extract the entire HTML code from your selection, this can be especially helpful when selecting entire DIVs on the page.
Extraction: Full HTML
Result: <span class="a-size-medium a-color-base a-text-normal">Samsung Galaxy A10 32GB (A105M) 6.2" HD+ Infinity-V 4G LTE Factory Unlocked GSM Smartphone - Black</span>
The Inner HTML extraction will extract any content found within the HTML tags of the selection you’ve made.
Extraction: Inner HTML
Result: Samsung Galaxy A10 32GB (A105M) 6.2" HD+ Infinity-V 4G LTE Factory Unlocked GSM Smartphone - Black
Attribute Extraction
In many cases, your selection will have HTML attributes such as class, ID or title.
ParseHub will automatically identify these attributes and allow you to extract the data enclosed within them.
In this example selection we have made, ParseHub has picked up the class attribute. We can now select it from the dropdown to extract that data specifically.
Extraction: class Attribute
Result: a-size-medium a-color-base a-text-normal
Building and Running your Scrape
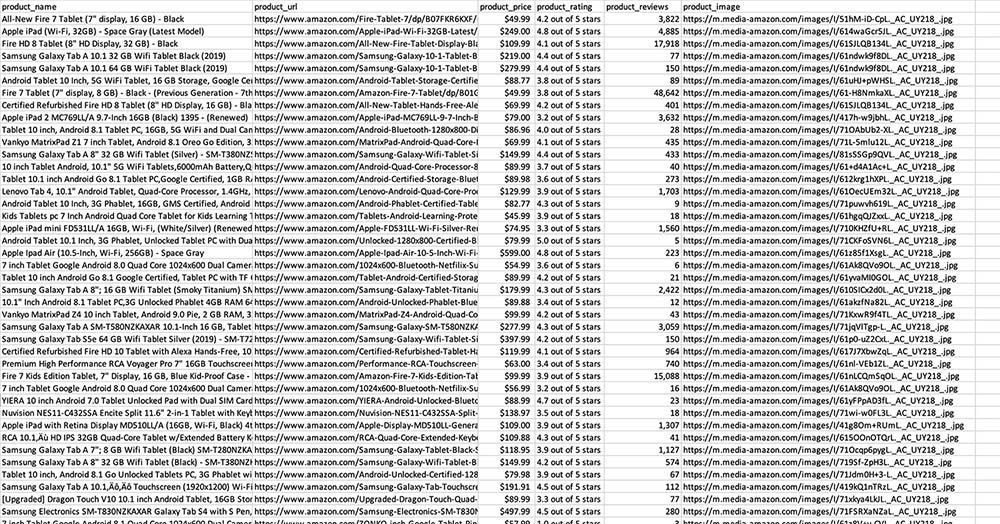
What we have setup today is a very simple scraping project, as it is only extracting the name and URL for each product in one page.
For a more in-depth guide on how to build a larger project (with your new HTML extraction skills), check out our tutorial on setting up a web scraping project.
By following our tutorial you will be able to extract data from any website and into a spreadsheet, including HTML data and attributes.
Ultimately, scraping HTML in 2023 is easy with ParseHub, and can save you a lot of time and money. If you're an enterprise business that needs help with large amounts of HTML scraping, check out ParseHub Plus.
You can also get one of our FREE Web Scraping Certifications. Enroll to one of our Web Scraping Certification courses today!
Happy Scraping!